Dynamics Generalisation with Behaviour Foundation Models
Training Agents with Foundation Models Workshop
2024-08-09
Problem Setup
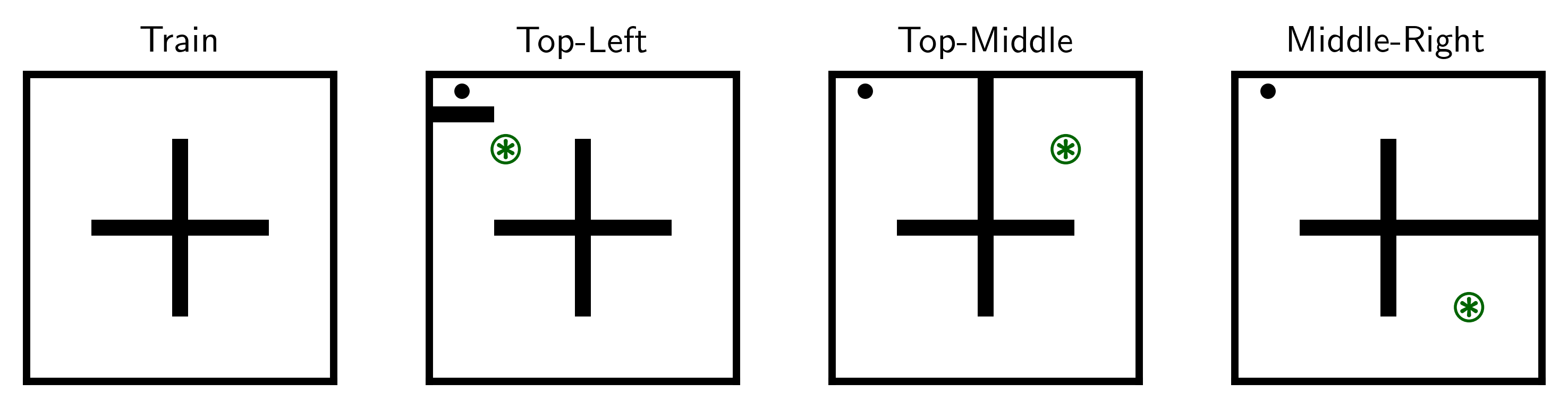
- Pre-train \(\pi(s,z)\) on offline dataset \(D_{\text{train}}\) from one env
- Collect datasets of transitions from \(N\) test envs \(\{D_{\text{test}}^1, \ldots, D_{\text{test}}^N\}\)
- Use \(\{D_{\text{test}}^1, \ldots, D_{\text{test}}^N\}\) to condition \(\pi(s, z)\) on test envs with changed dynamics
Method: Contextual BFMs
BFMs conventionally infer \(z\) from \(D_{\text{train}}\) via:
\(z \approx \mathbb{E}_{(s_t, a_t, s_{t+1}) \sim D_{\text{train}}} \big[R(s_t, a_t, s_{t+1}) B(s_t, a_t, s_{t+1})\big]\)
Key idea: downweight \(R\) for transitions not possible under changed dynamics
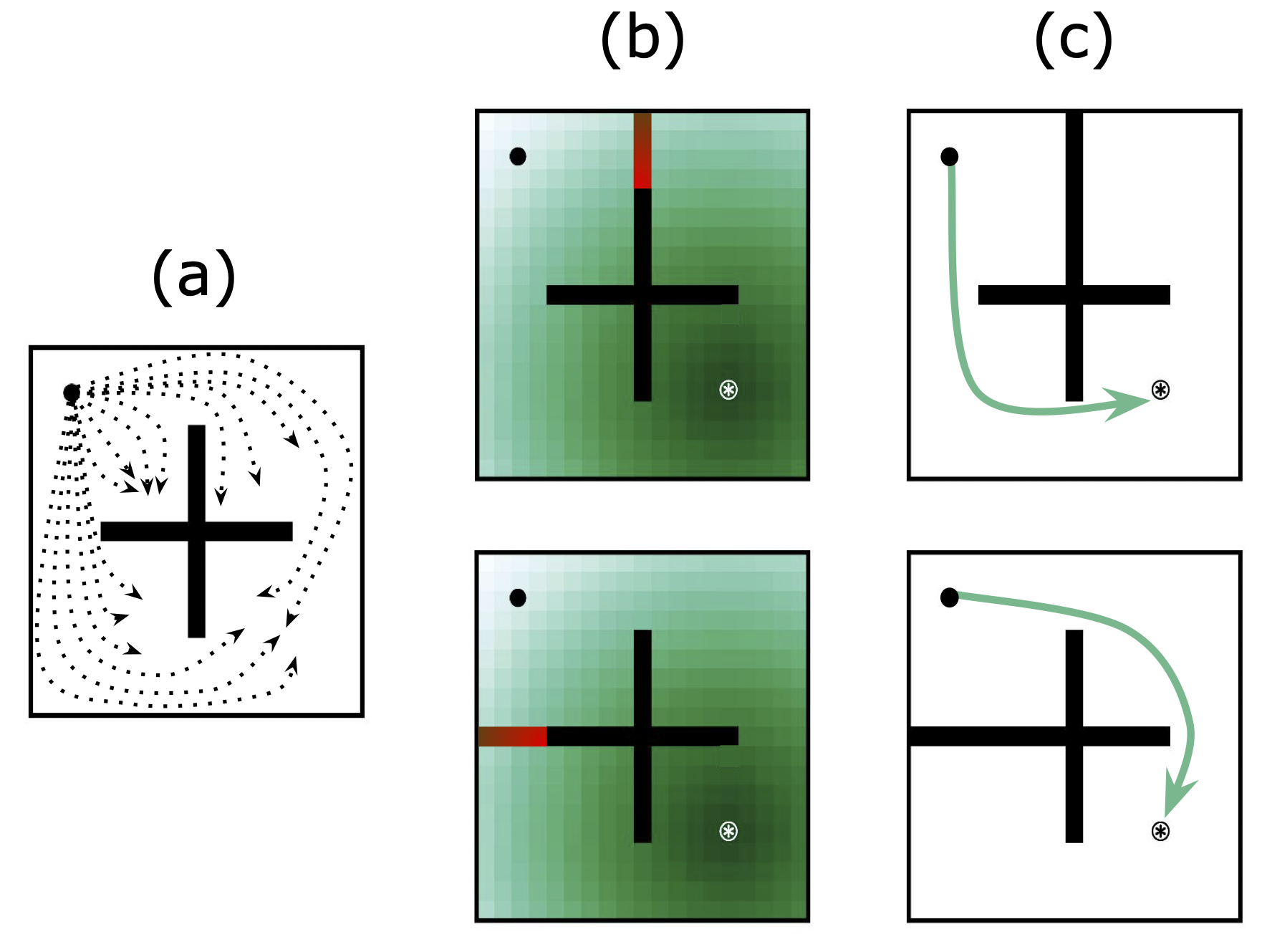
- Collect \(\{D_{\text{test}}^1, \ldots, D_{\text{test}}^N\}\).
- Train classifiers \({\color{blue}{f_{(s_t,a_t)}}}\) and \({\color{red}{f_{(s_t,a_t,s_{t+1})}}}\) to distinguish between train and test envs.
- Calculate reward augmentation for each transition (from [2]): \({\color{green}{\Delta R}} = {\color{red}{\log p (test|s_t, a_t, s_{t+1})}} - {\color{blue}{\log p(test|s_t, a_t)}}\) \(- {\color{red}{\log(train | s_t, a_t, s_{t+1})}} + {\color{blue}{\log p(train | s_t, a_t)}}\)
- Infer z with augmented rewards:
\(z \approx \mathbb{E}_{(s_t, a_t, s_{t+1}) \sim D_{\text{train}}} \big[(R(s_t, a_t, s_{t+1}) + {\color{green}{\Delta R}}) B(s_t, a_t, s_{t+1})\big]\)
- Pass \(z\) to \(\pi(s,z)\)
Preliminary Results
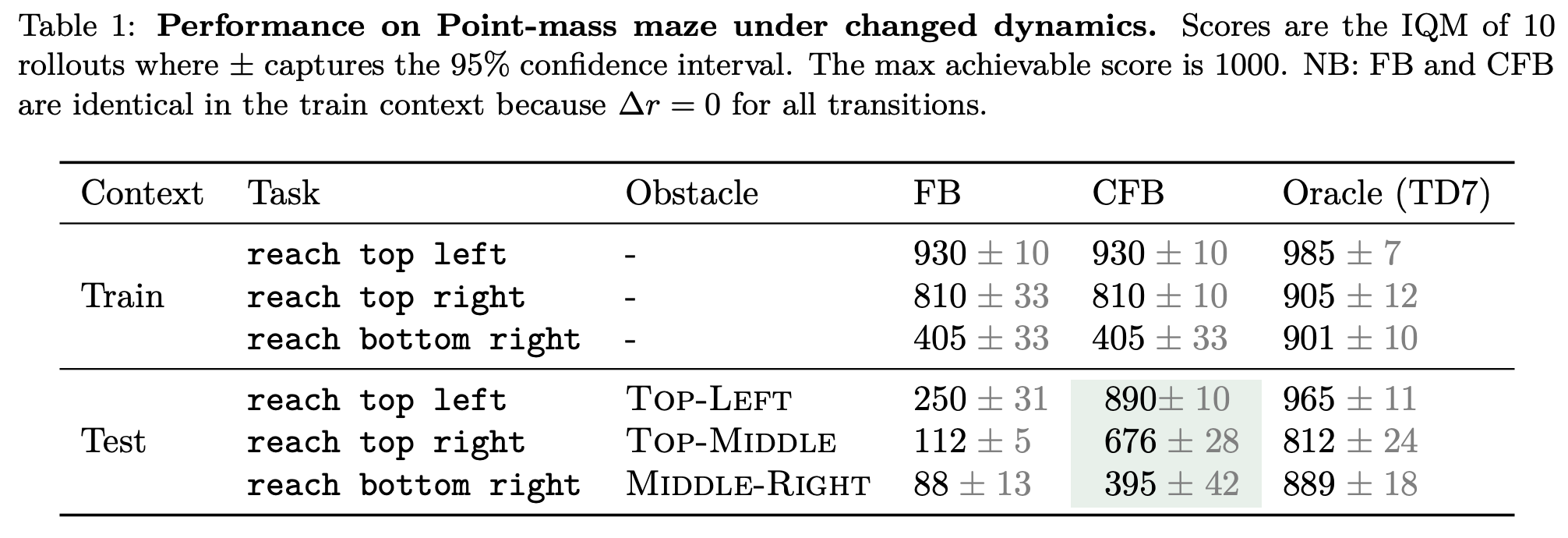
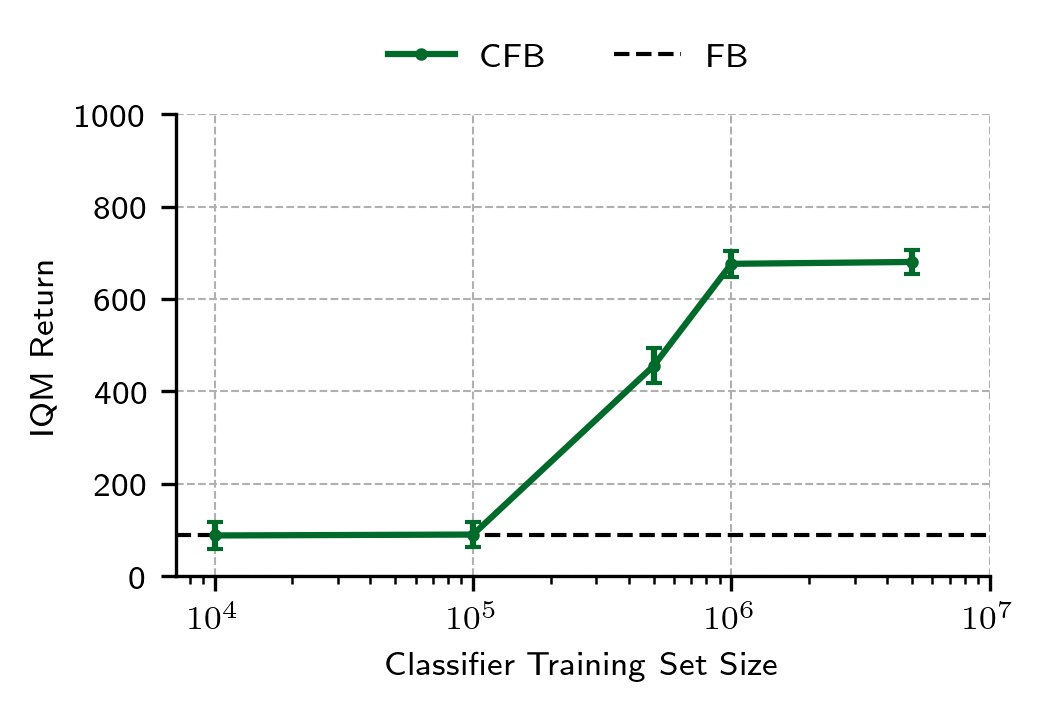
Limitations
Thanks!
Paper

Twitter: @enjeeneer
Website: https://enjeeneer.io
![]()