On Zero-Shot Reinforcement Learning
PhD Viva
RL + Perfect Simulators + Compute = Superhuman
RL + Perfect Simulators + Compute = Superhuman
The Case for Zero-Shot RL
- Zero-shot RL methods aim to handle this discrepancy quickly
- Impressive progress has been made if the gap between the learned simulator and the real-world is small
- I contend that to solve real-world problems these methods need to deal with a larger gap and satisfy:
![]()


Chapter 3: Zero-shot RL from Low Quality Data
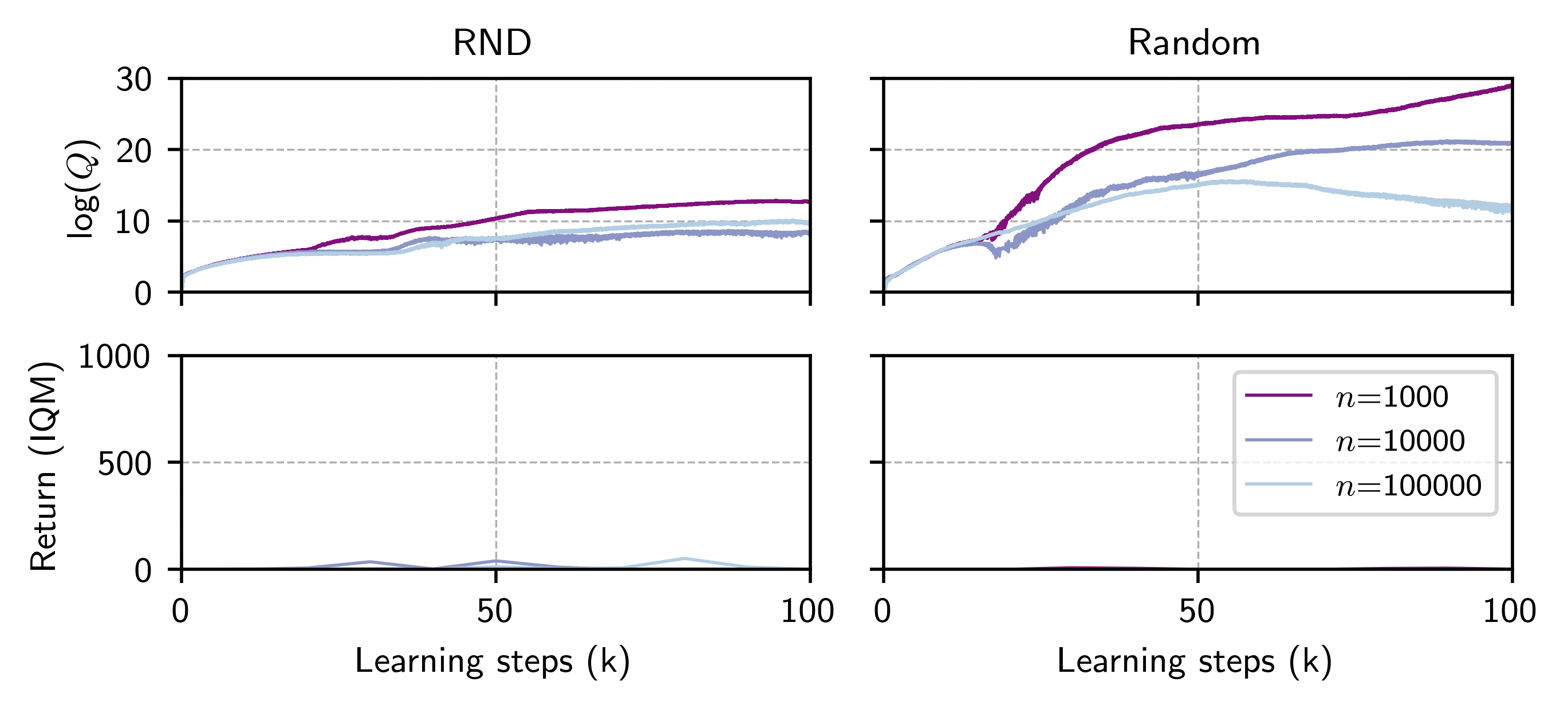
Failure mode: out-of-distribution value overestimation [4]
Chapter 3: Zero-shot RL from Low Quality Data
Failure mode: out-of-distribution value overestimation [4]
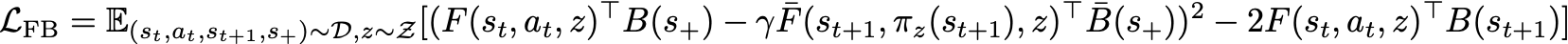
Chapter 3: Zero-shot RL from Low Quality Data
Failure mode: out-of-distribution value overestimation [4]
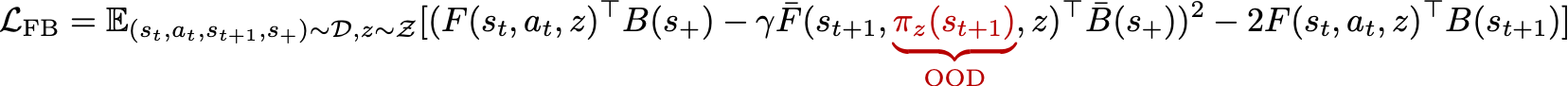
Chapter 3: Zero-shot RL from Low Quality Data
Conservative Zero-shot RL

Chapter 3: Zero-shot RL from Low Quality Data
Conservative Zero-shot RL
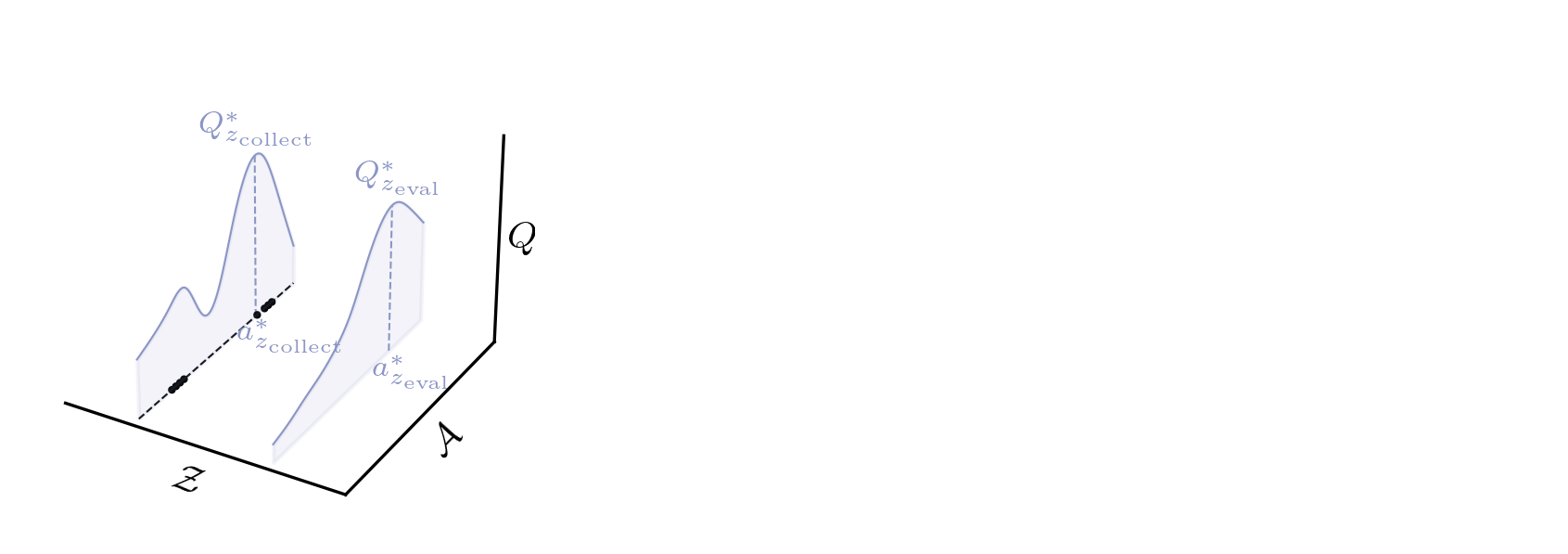
Chapter 3: Zero-shot RL from Low Quality Data
Conservative Zero-shot RL
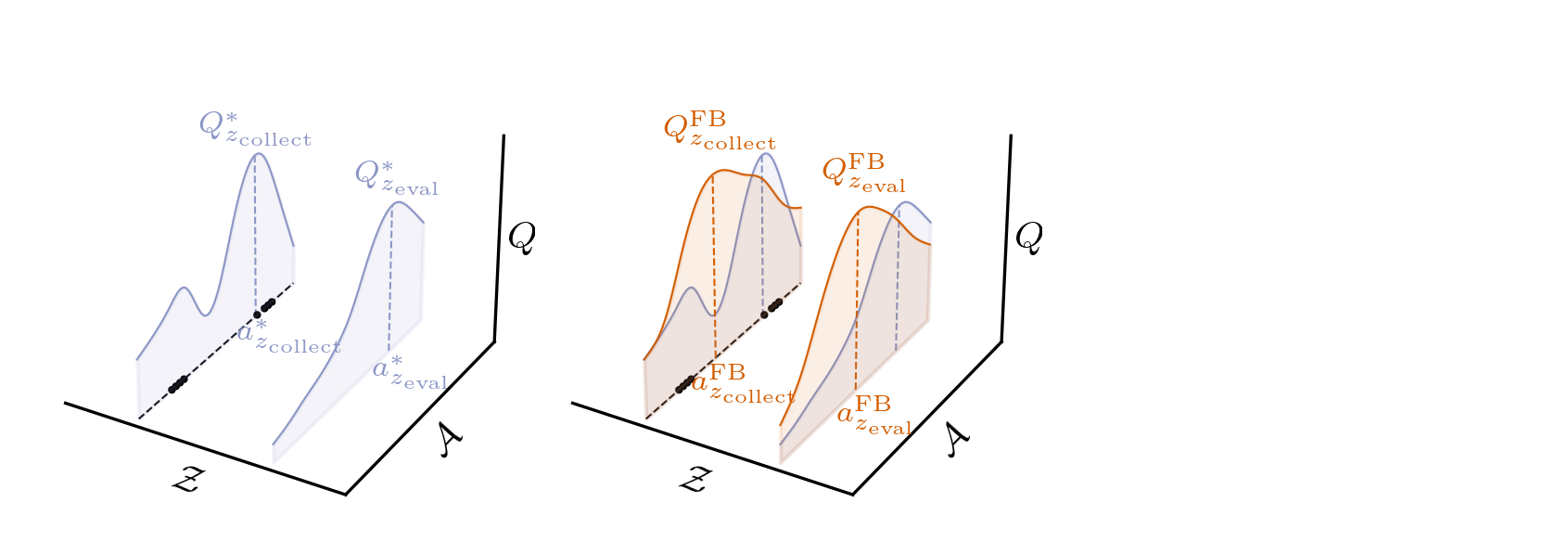
Chapter 3: Zero-shot RL from Low Quality Data
Conservative Zero-shot RL
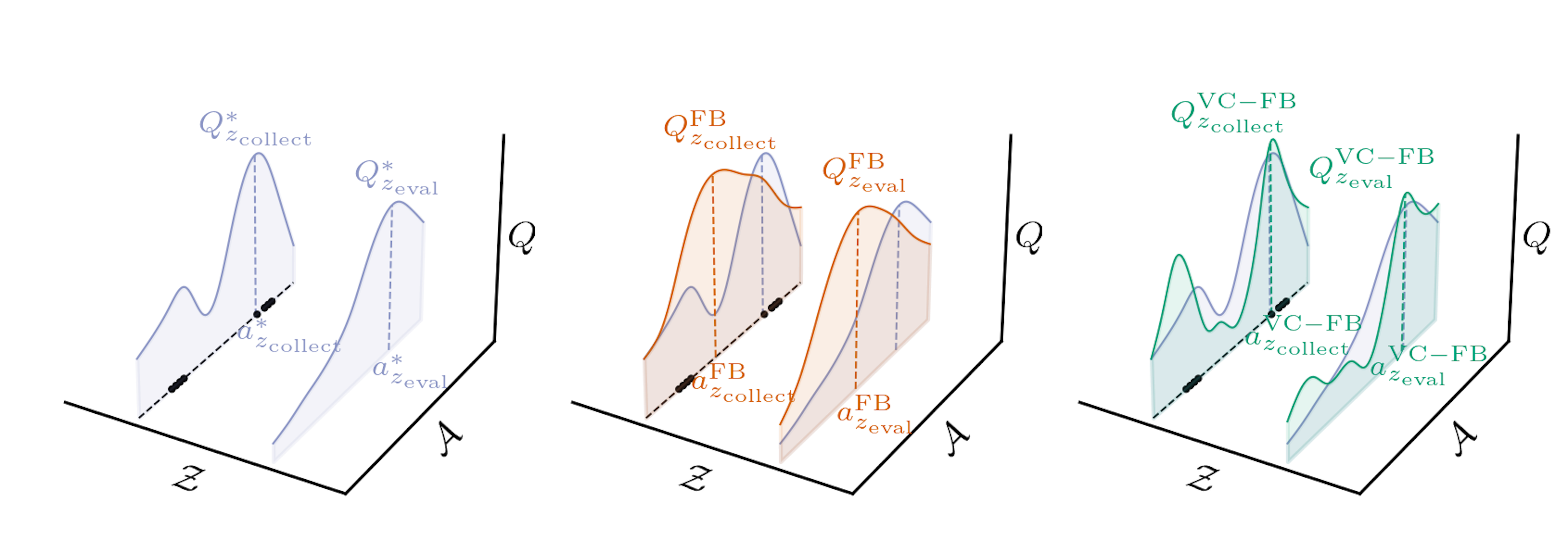


Chapter 3: Zero-shot RL from Low Quality Data
ExORL Experiments
Baselines
- Zero-shot RL: FB [2], SF-LAP [6]
- Goal-conditioned RL: GC-IQL [7]
- Offline RL: CQL [5]
Datasets

Chapter 3: Zero-shot RL from Low Quality Data
ExORL Results
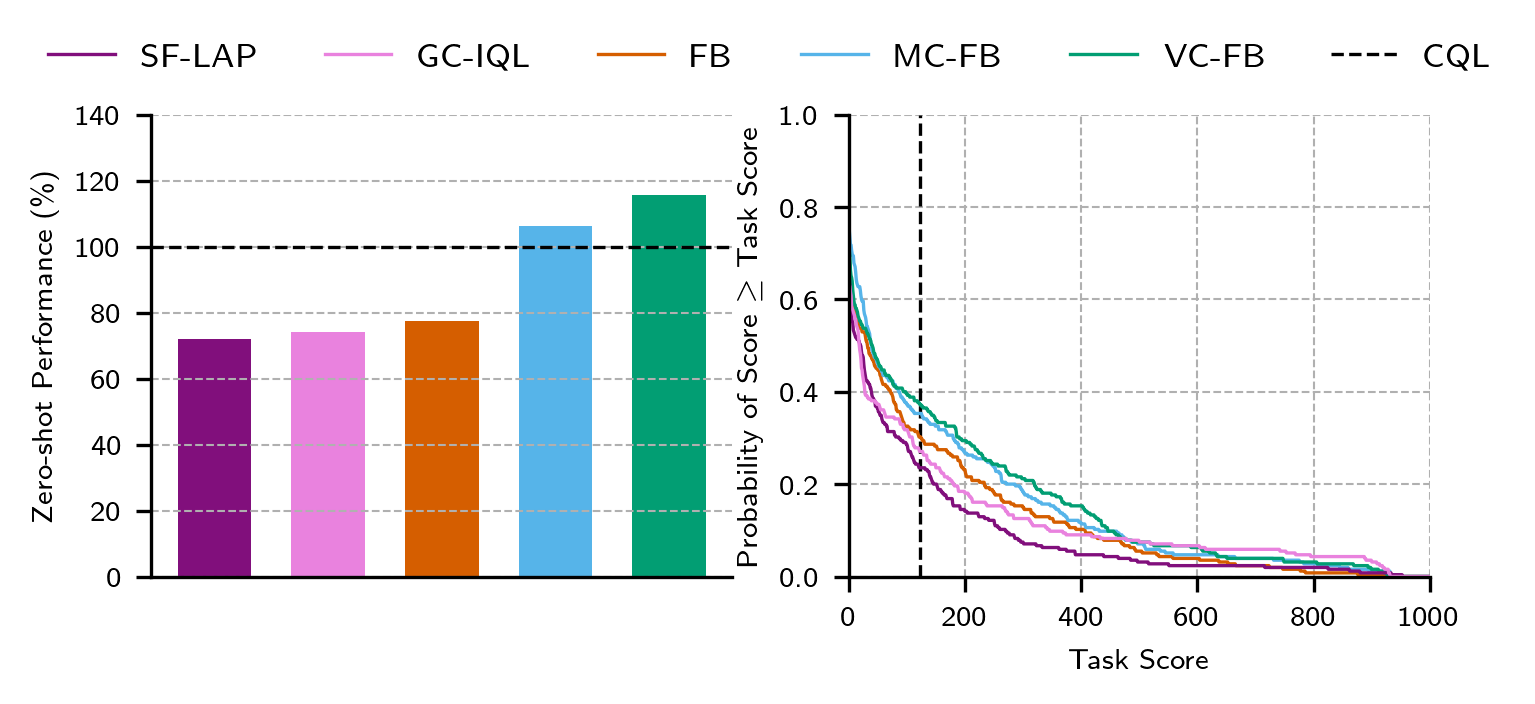
Chapter 3: Zero-shot RL from Low Quality Data
D4RL Results
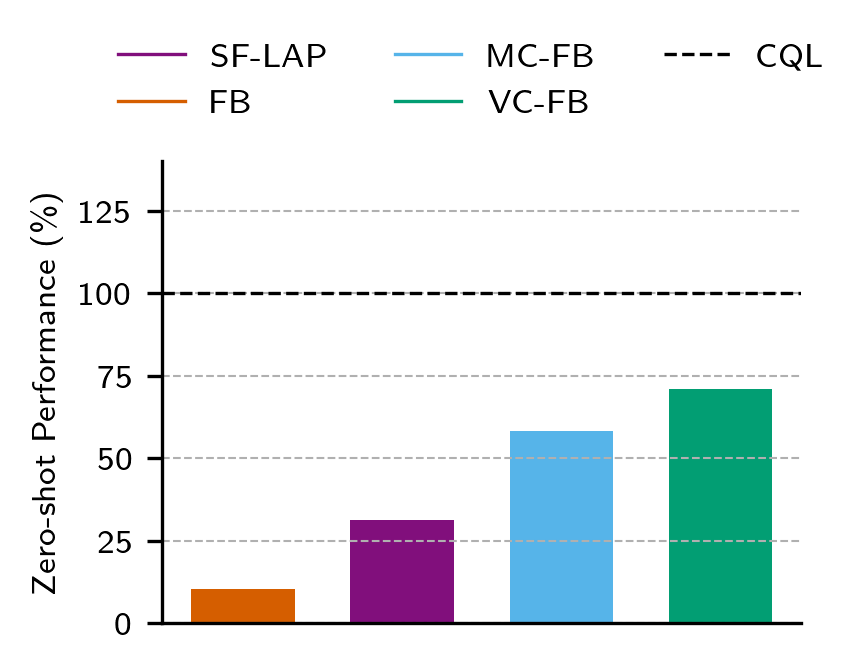
Chapter 3: Zero-shot RL from Low Quality Data
Performance on Idealised Datasets is Unaffected
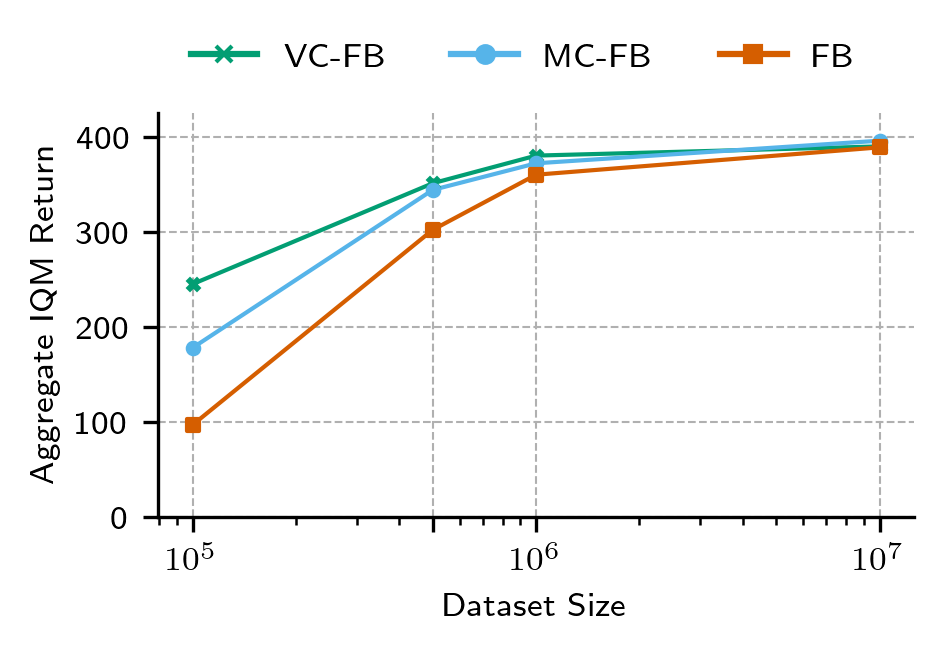
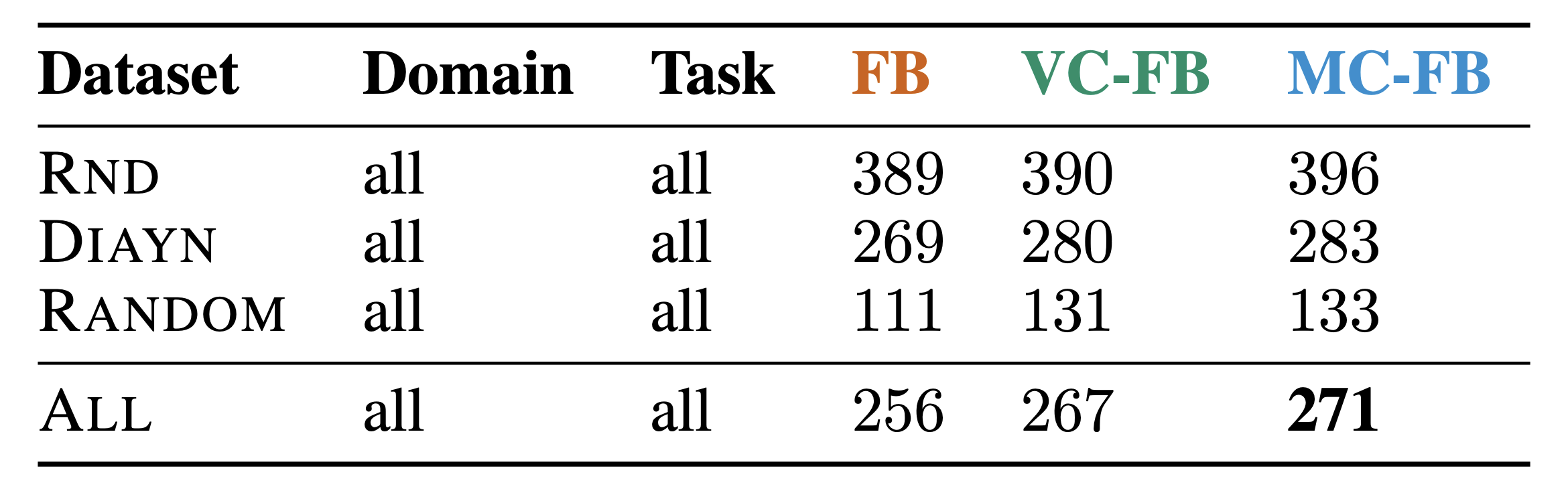
Chapter 4: Zero-shot RL under Partial Observability
Failure mode: state and task mis-identification
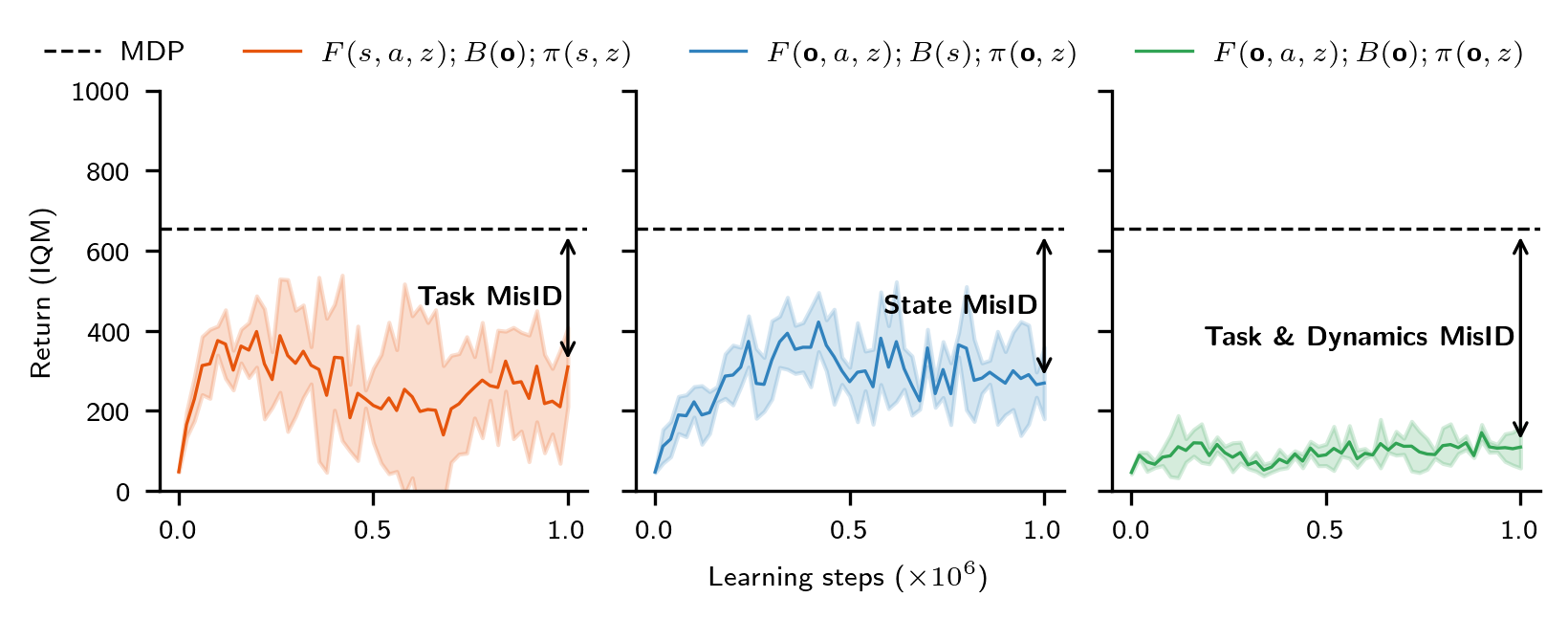


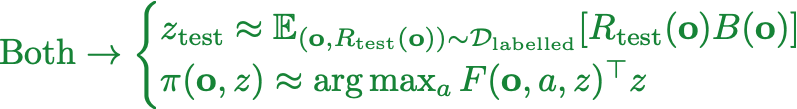
Chapter 4: Zero-shot RL under Partial Observability
Memory-based Zero-shot RL methods
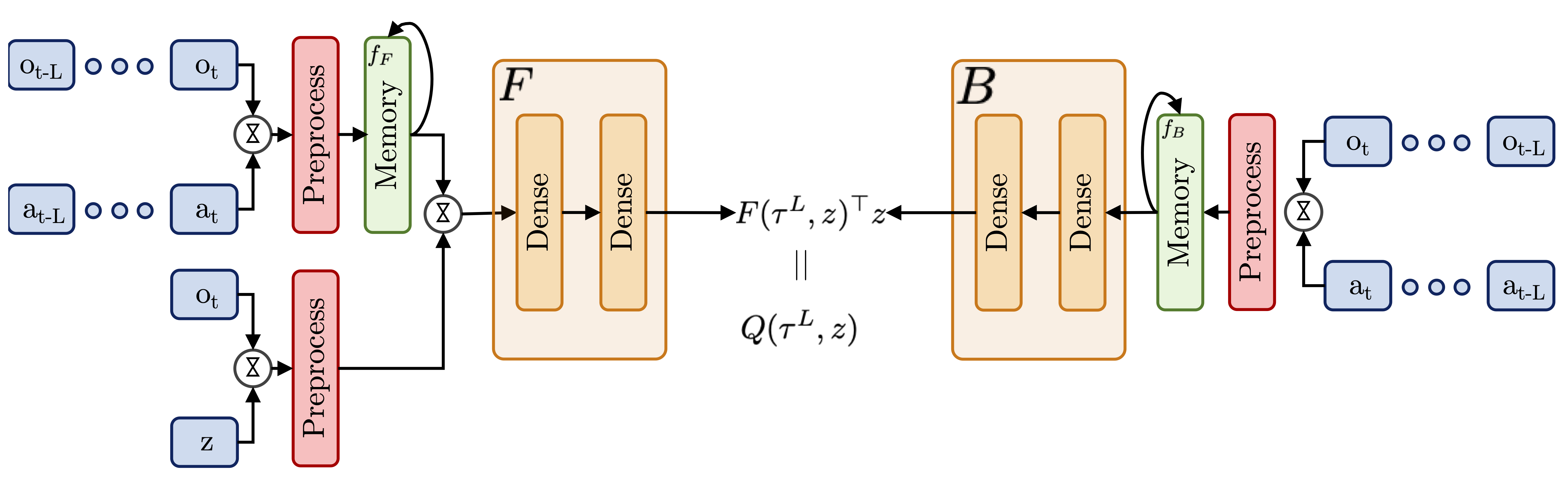
Chapter 4: Zero-shot RL under Partial Observability
Standard POMDPs
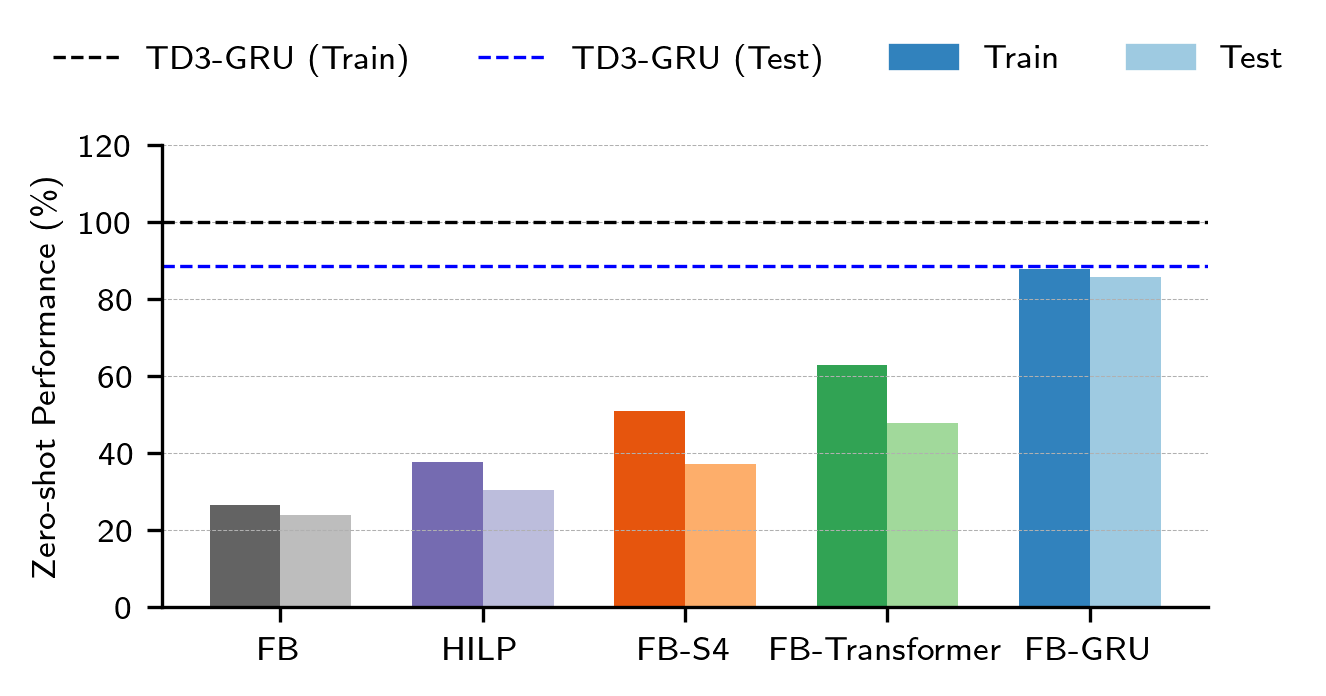
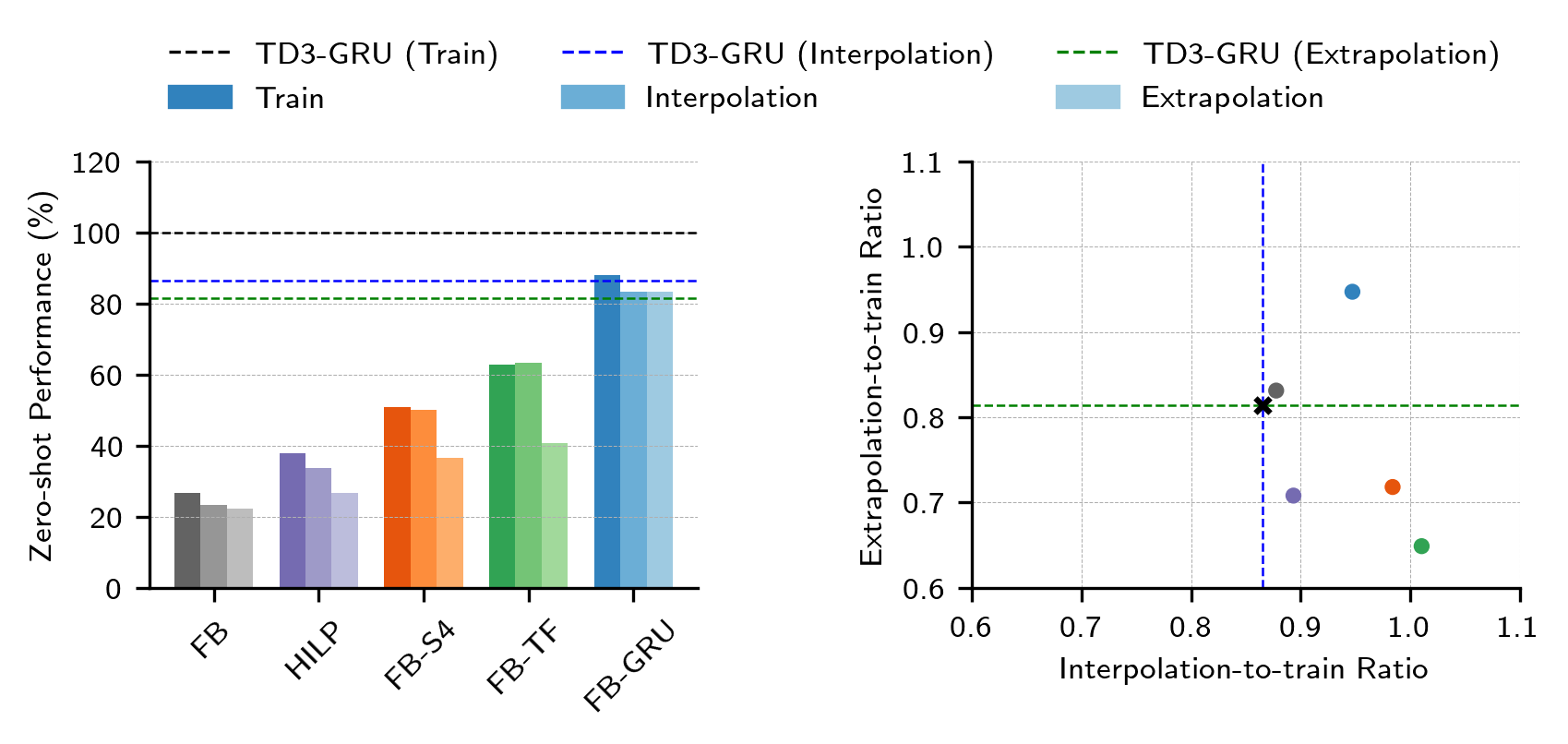
Chapter 4: Zero-shot RL under Partial Observability
Generalisation
Chapter 5: Zero-shot RL with No Prior Data
Low Emission Building Control

Chapter 5: Zero-shot RL with No Prior Data
Low Emission Building Control
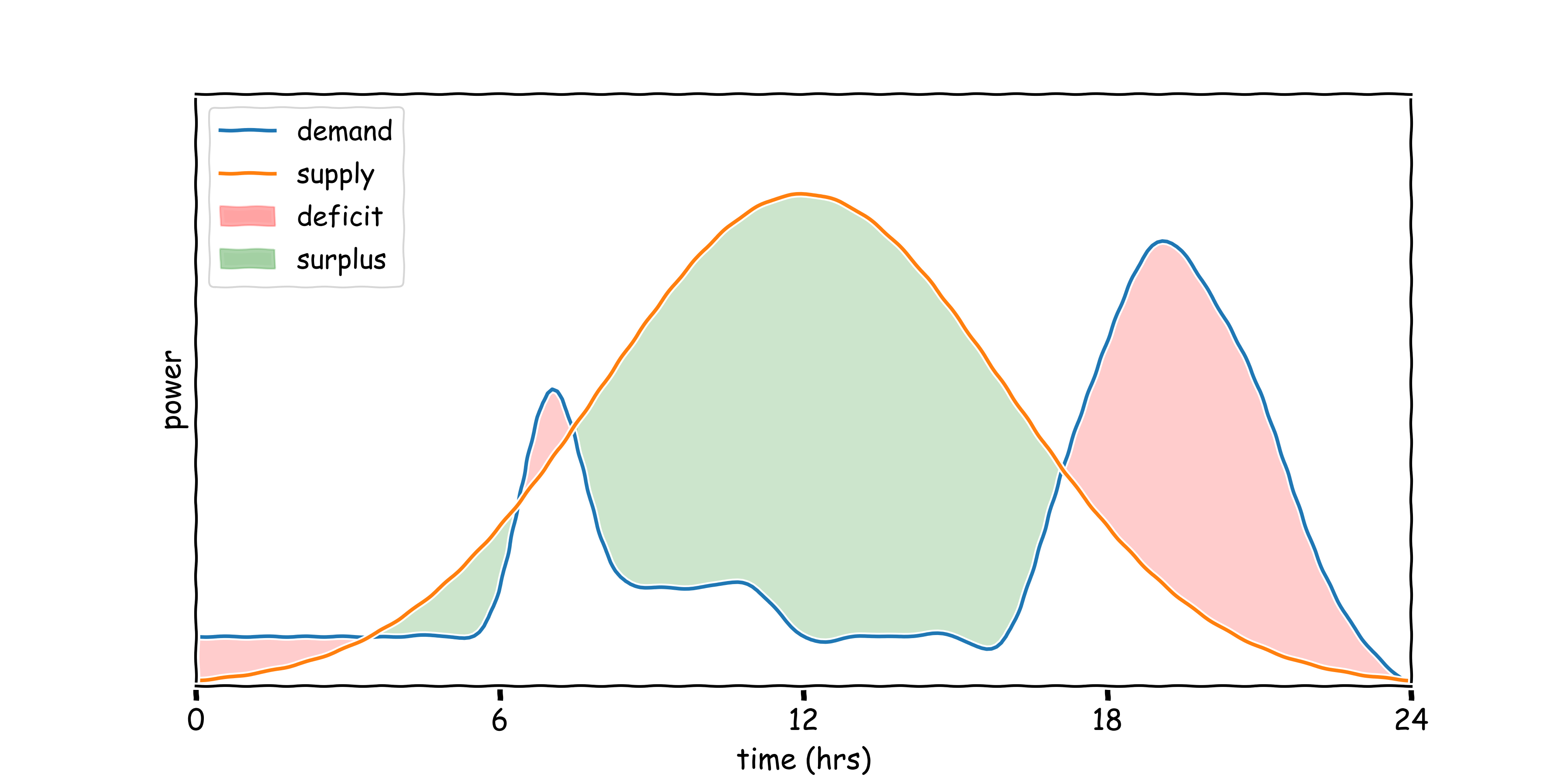
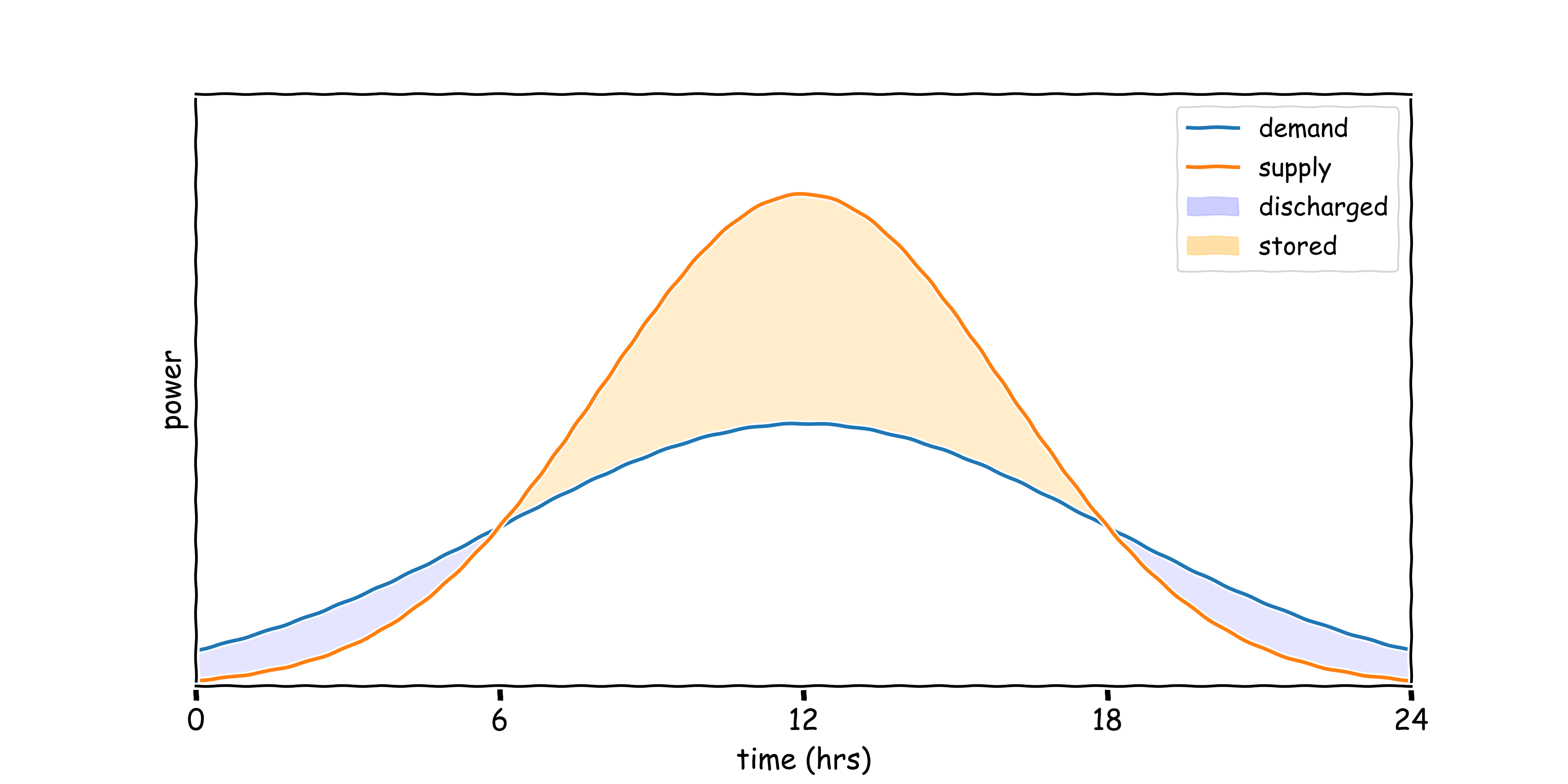
Chapter 5: Zero-shot RL with No Prior Data
PEARL: Probabilistic Emission Abating Reinforcement Learning
Chapter 5: Zero-shot RL with No Prior Data
Energym Results
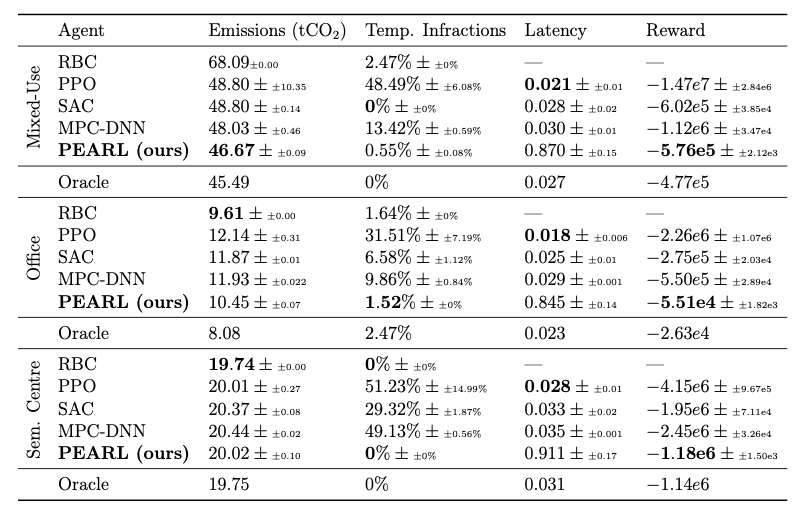
Chapter 5: Zero-shot RL with No Prior Data
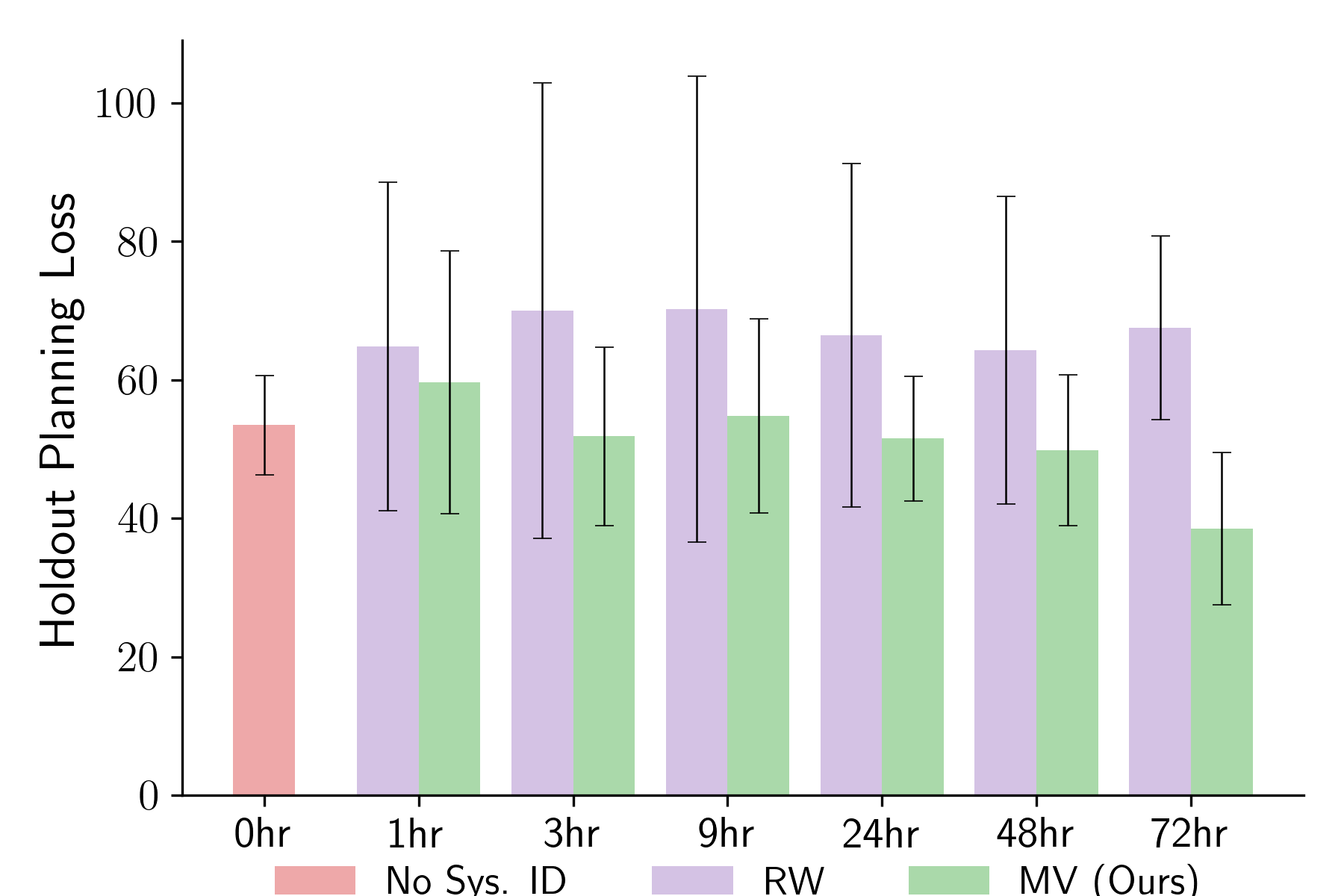
System Identification
Conclusions
I set out to defend the following thesis:
- In Chapter 3, I took steps toward addressing the data quality constraint with conservative zero-shot RL methods
- In Chapter 4, I took steps toward addressing the observability constraint with memory-based zero-shot RL methods
- In Chapter 5, I took steps to addressing the data availability constraint (in the context of buidling control) with PEARL