Low Emission Building Control with Zero-Shot Reinforcement Learning
AAAI 2023
In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 37, No. 12, pp. 14259-14267)
Scott R. Jeen\(^{1,3}\), Alessandro Abate\(^{2,3}\), Jonathan M. Cullen\(^{1}\)
\(^{1}\) University of Cambridge
\(^{2}\) University of Oxford
\(^{3}\) Alan Turing Institute
[Paper] [Code] [Talk] [Poster]
PEARL: Probabilistic Emission-Abating Reinforcement Learning

Presenting PEARL: Probabilistic Emission-Abating Reinforcement Learning, a deep RL algorithm that can find performant building control policies online, without pre-training–the first time this has been shown to be possible. We show PEARL can reduce annual emissions by 31% when compared with a conventional controller whilst maintaining thermal comfort, and outperforms all RL baselines used for comparison. PEARL is simple to commission, requiring no historical data or simulator access in advance, paving a path towards general solutions that could control any building. The scaled deployment of such systems could prove a cost-effective method for tackling climate change.
Contact. If you want to chat about this work, please feel free to reach out to me at: srj38@cam.ac.uk
Abstract
Heating and cooling systems in buildings account for 31% of global energy use, much of which are regulated by Rule Based Controller (RBCs) that neither maximise energy efficiency nor minimise emissions by interacting optimally with the grid. Control via Reinforcement Learning (RL) has been shown to significantly improve building energy efficiency, but existing solutions require access to building-specific simulators or data that cannot be expected for every building in the world. In response, we show it is possible to obtain emission-reducing policies without such knowledge a priori – a paradigm we call zero-shot building control. We combine ideas from system identification and model-based RL to create PEARL: Probabilistic Emission-Abating Reinforcement Learning and show that a short period of active exploration is all that is required to build a performant model. In experiments across three varied building energy simulations, we show PEARL outperforms an existing RBC once, and popular RL baselines in all cases, reducing building emissions by as much as 31% whilst maintaining thermal comfort.
Emissions Reduction and Thermal Performance
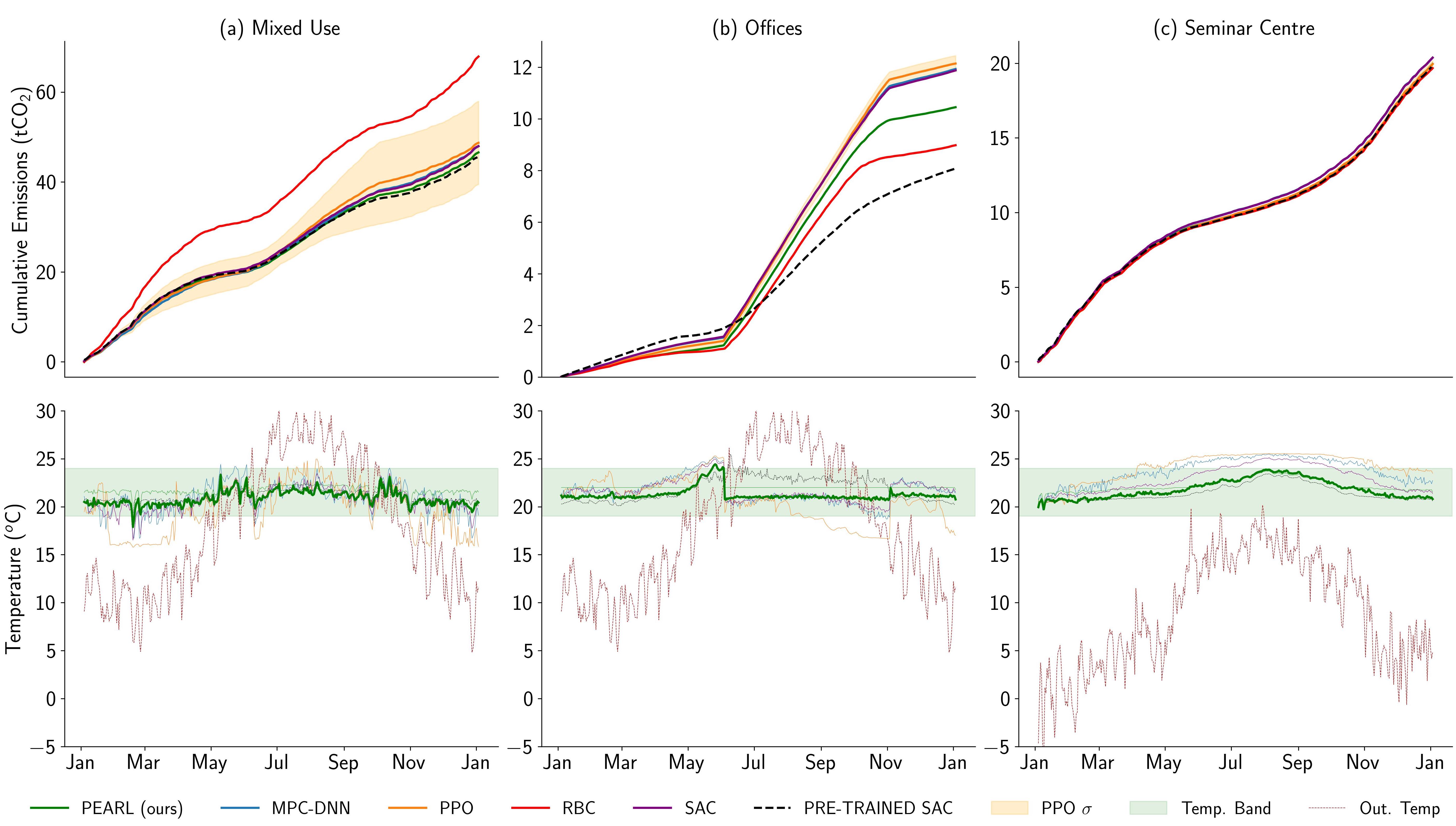
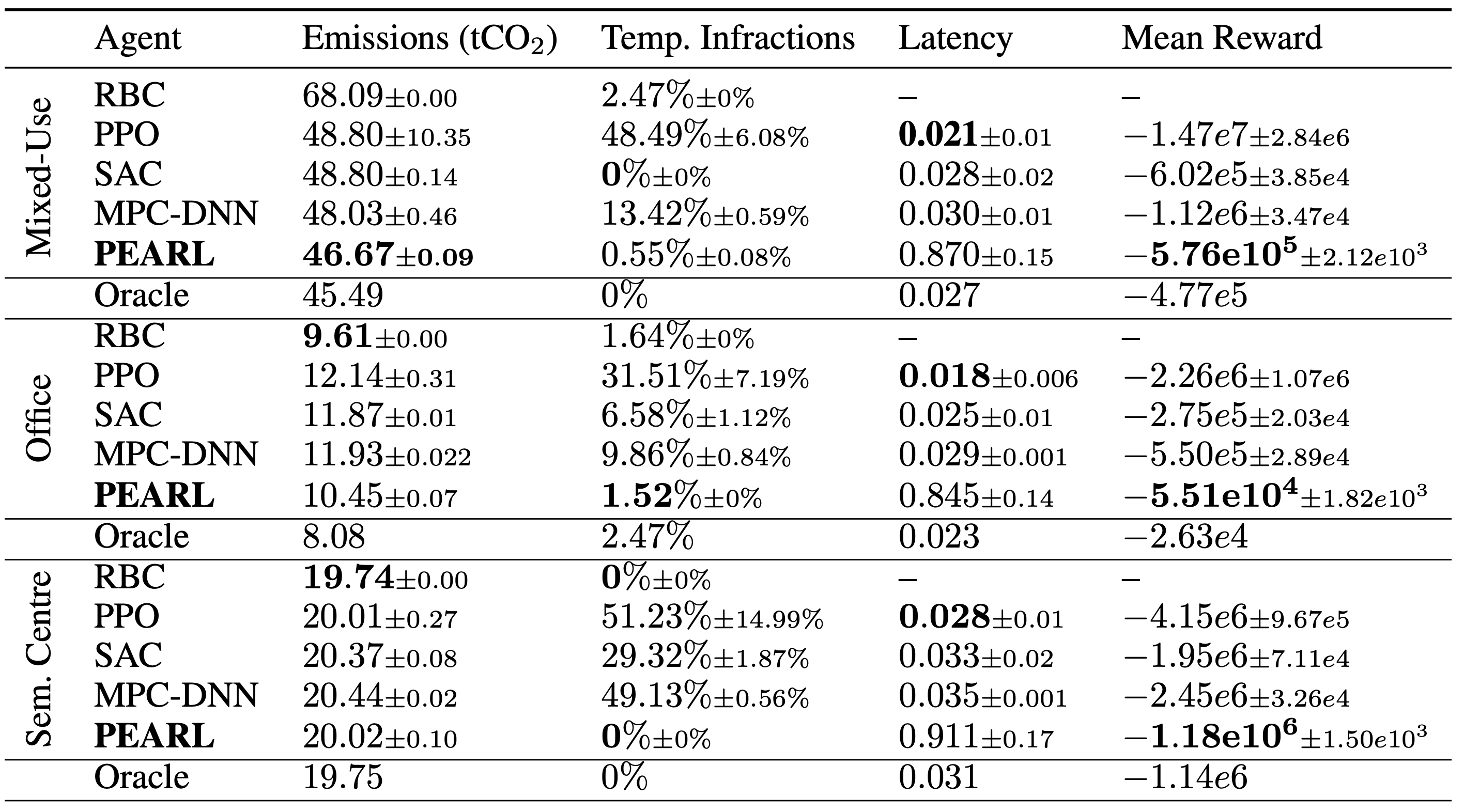
We test PEARL in three varied building simulations with differing geographies, topologies and thermal properties. We show reduce emissions from one industrial facility by 31%, and maintain mean building temperature within the required bounds for \(\geq\)97% of the year across all buildings.
Load Shifting
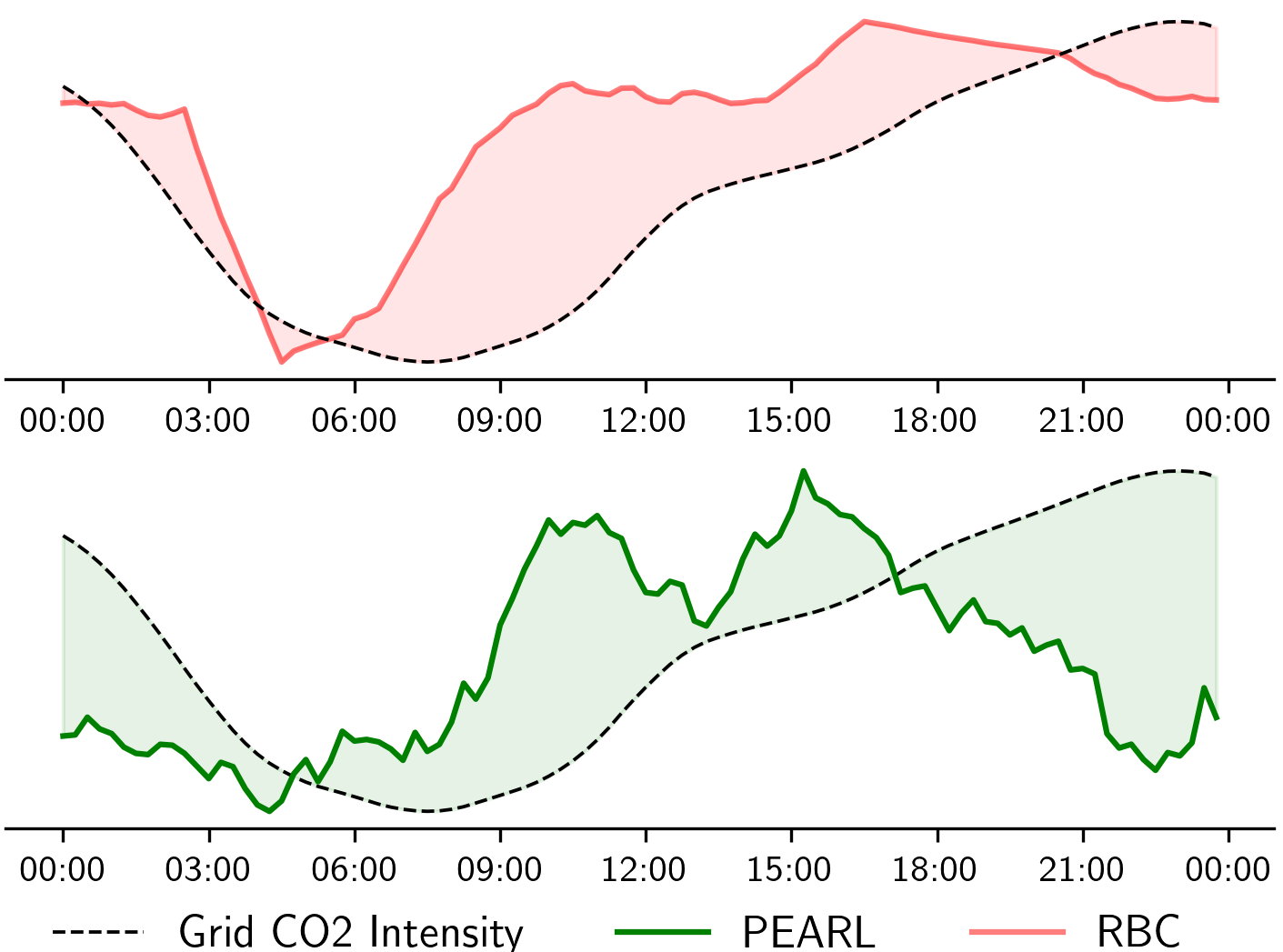
PEARL autonomously shifts energy demand to periods of the day where grid carbon intensity is low, a procedure analagous to Demand Response.
Probabilistic Deep RL
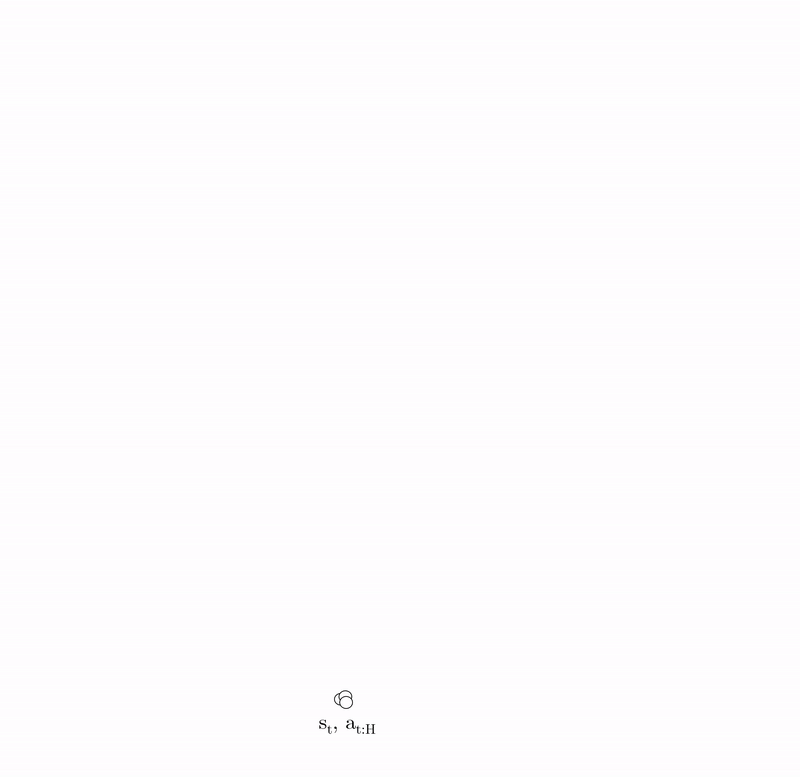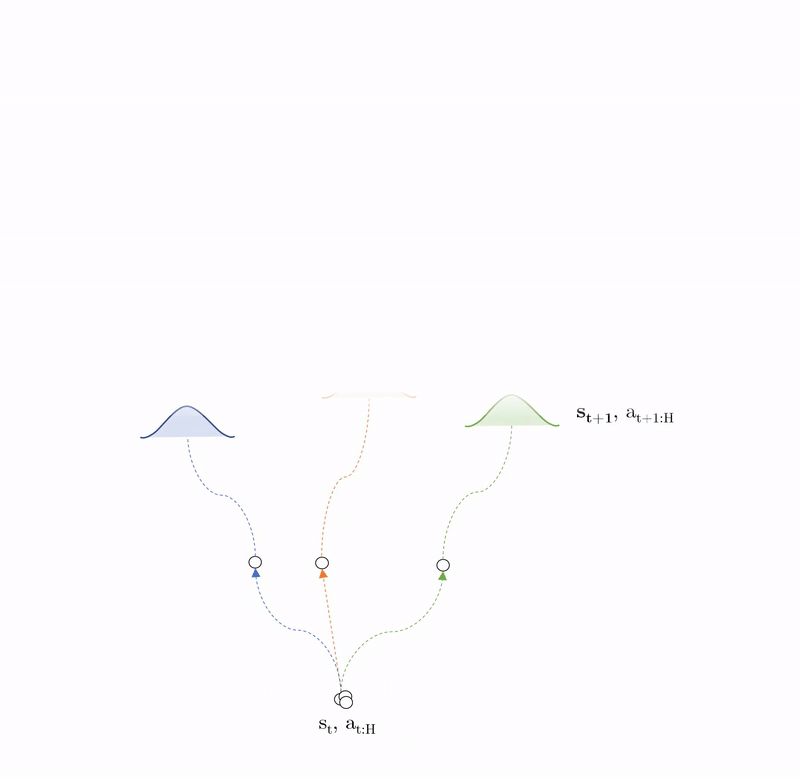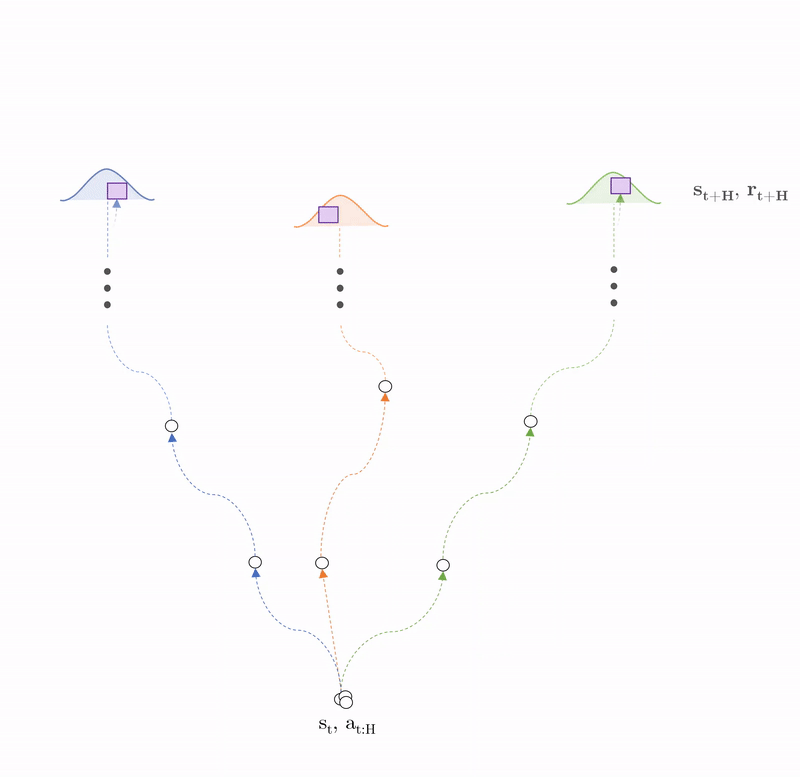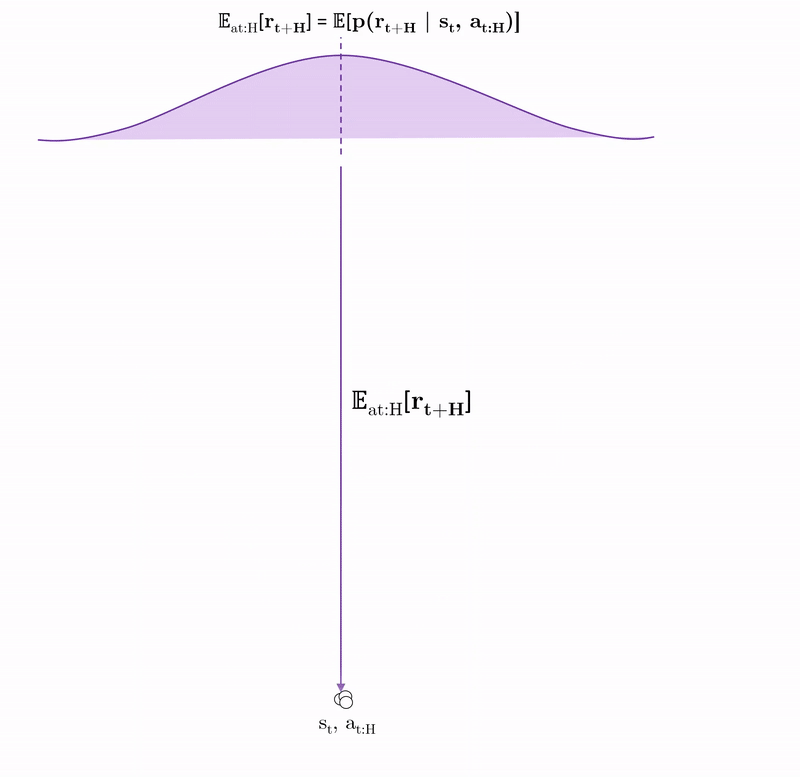
We can decompose PEARL into three steps.
- System ID: the agent takes actions to explore parts of the state-space with highest predictive variance \(V_{\Gamma}^*\) to maximise information gain.
- Prediction: system dynamics modelled as an ensemble of probabilistic deep neural networks.
- Control: trajectory sampling used to predict future rewards \(G_\Gamma\) of one action sequence \(a_{t:H-1}\), which is compared with many others to find the trajectory with optimal return \(G^*_\Gamma\).

Paper

Citation
If you find this work informative please consider citing the paper:
@inproceedings{jeen2023low,
title={Low emission building control with zero-shot reinforcement learning},
author={Jeen, Scott and Abate, Alessandro and Cullen, Jonathan M},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={37},
number={12},
pages={14259--14267},
year={2023}
}
6a8eb44 @ 2024-04-09