Zero-Shot Reinforcement Learning from Low Quality Data
NeurIPS 2024
Out-of-distribution Value Overestimation in BFMs
Out-of-distribution Value Overestimation in BFMs

Out-of-distribution Value Overestimation in BFMs
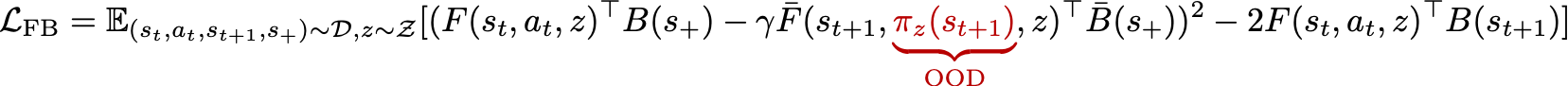
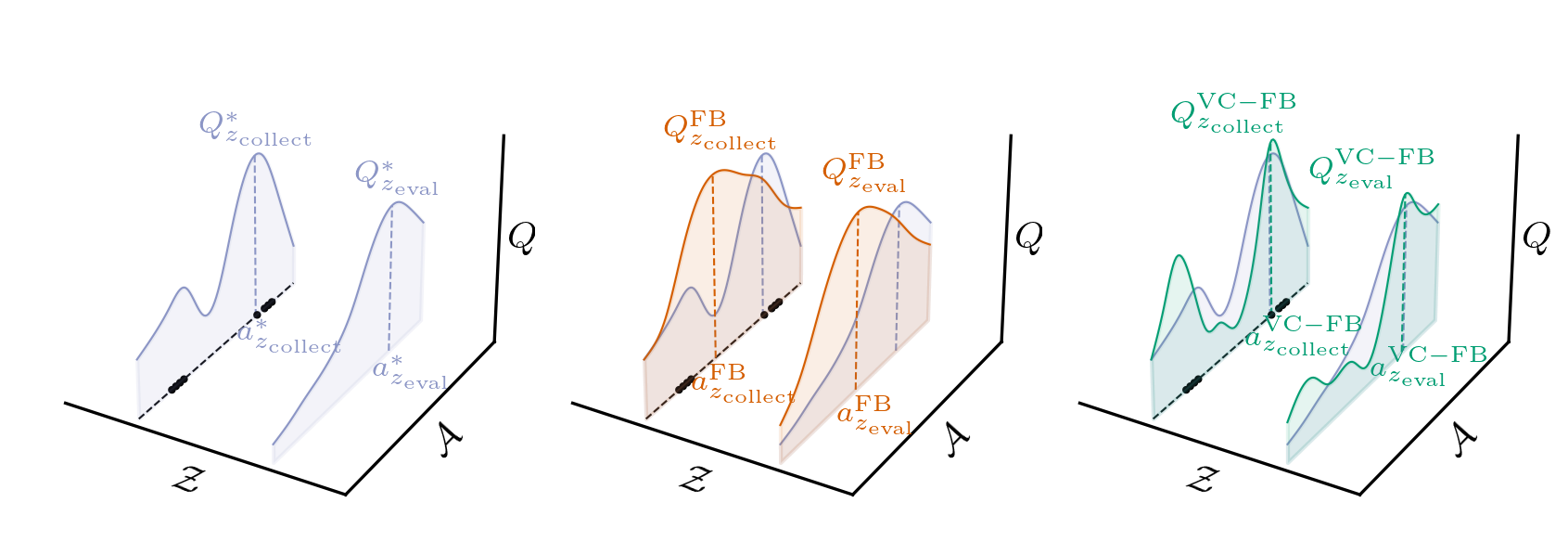
Conservative BFMs
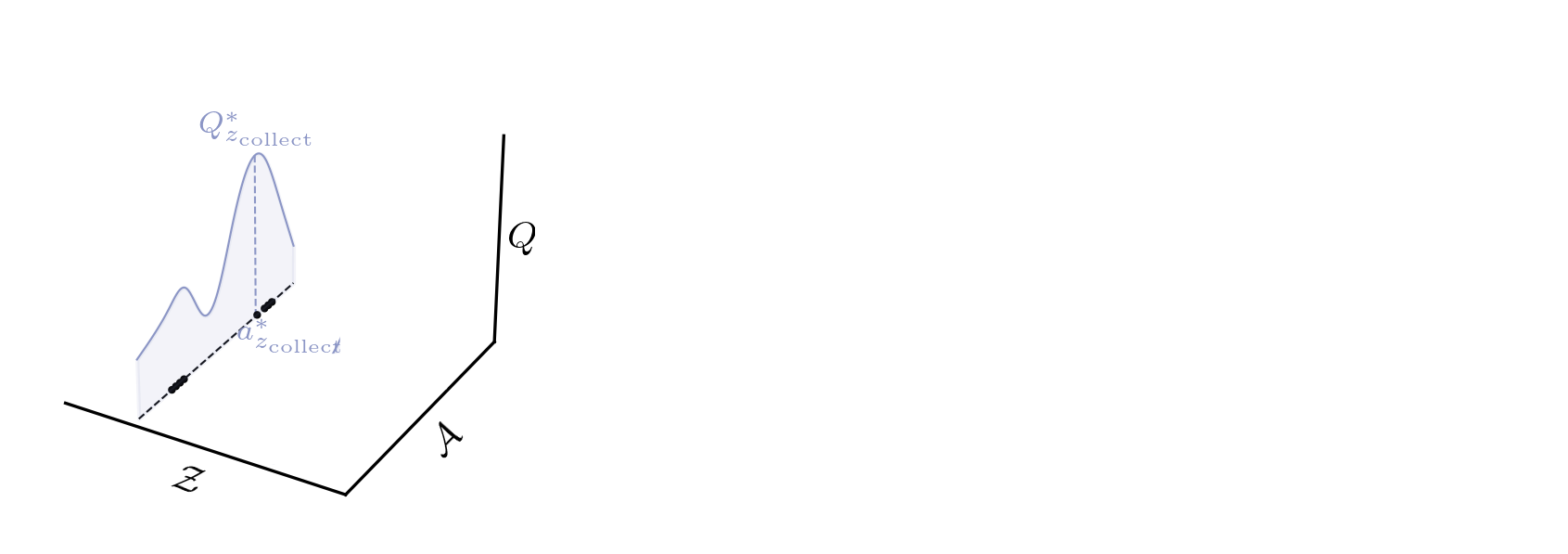
Conservative BFMs
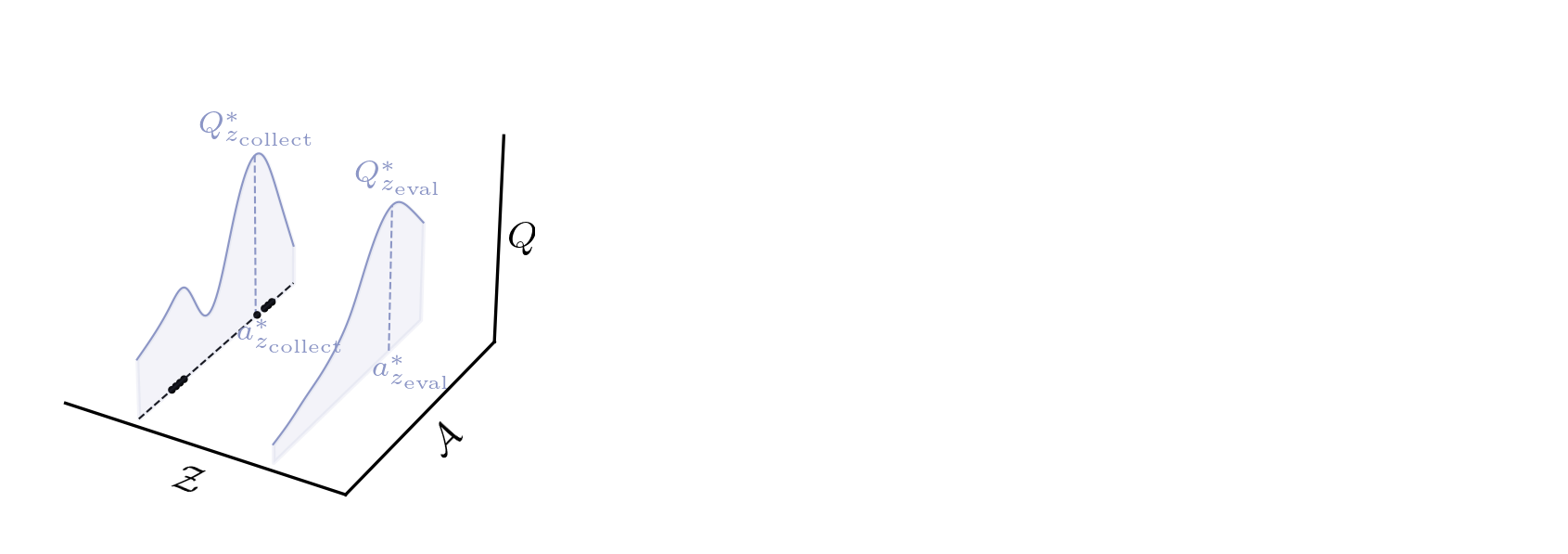
Conservative BFMs
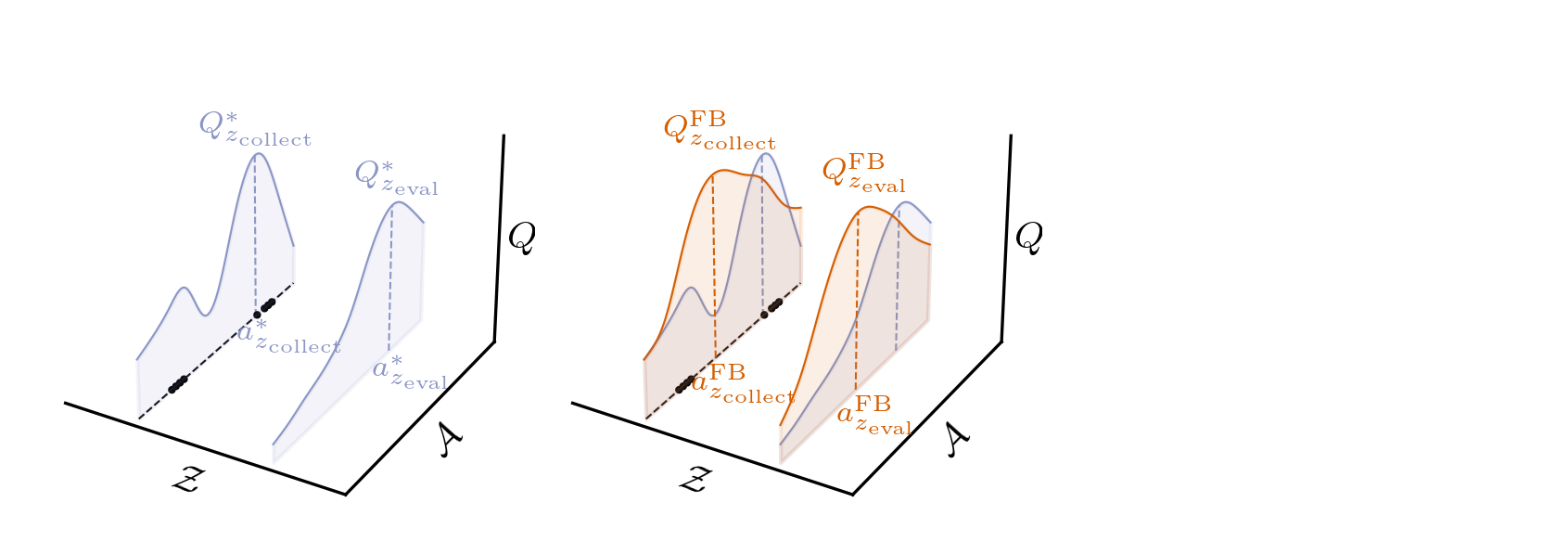
Conservative BFMs


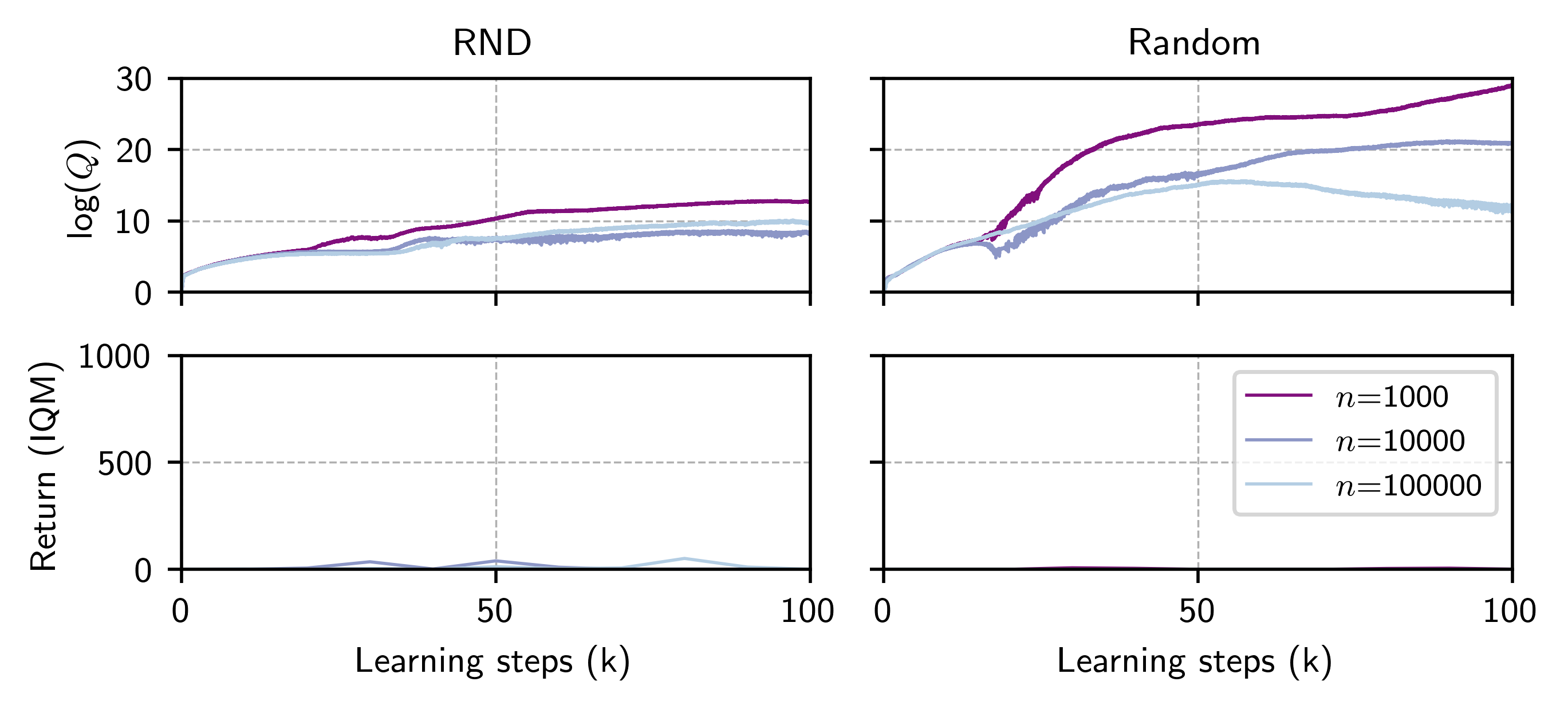
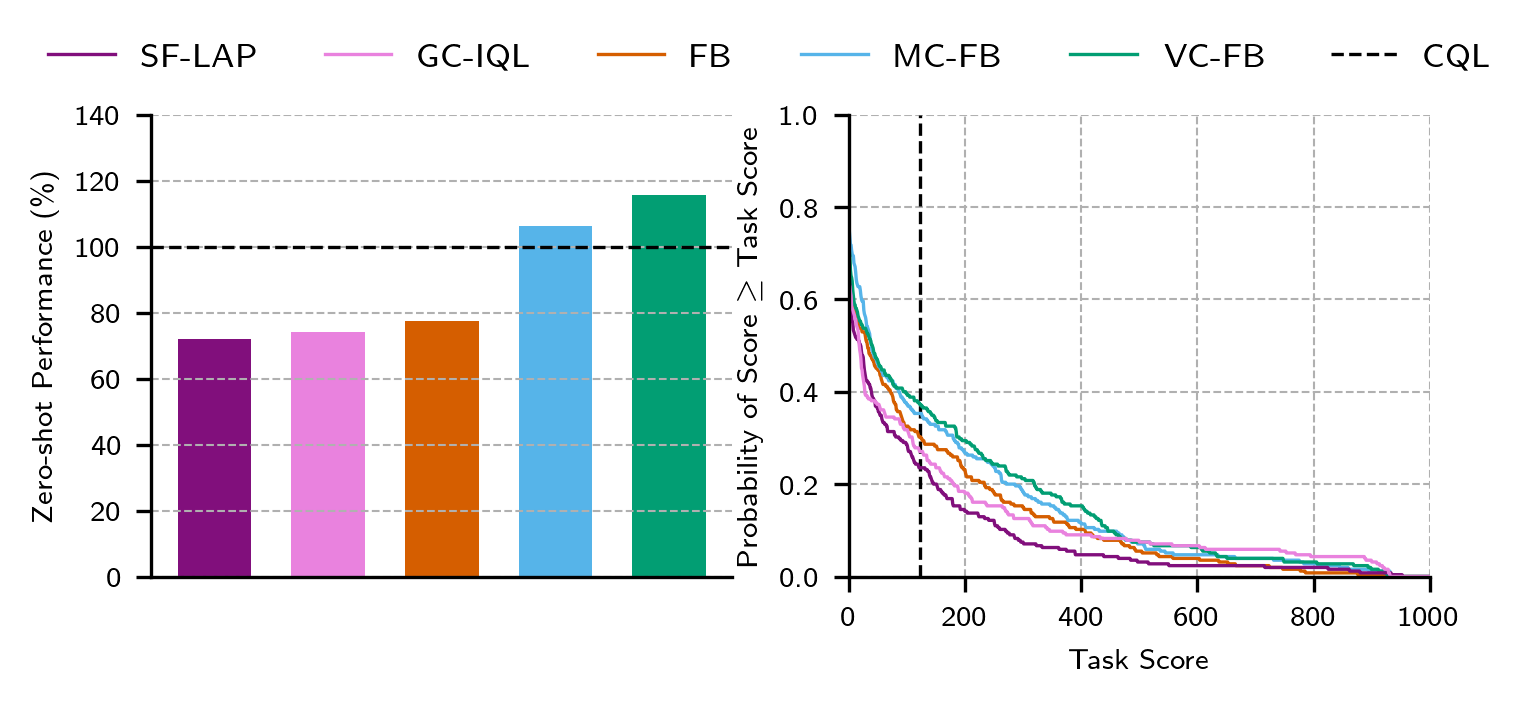
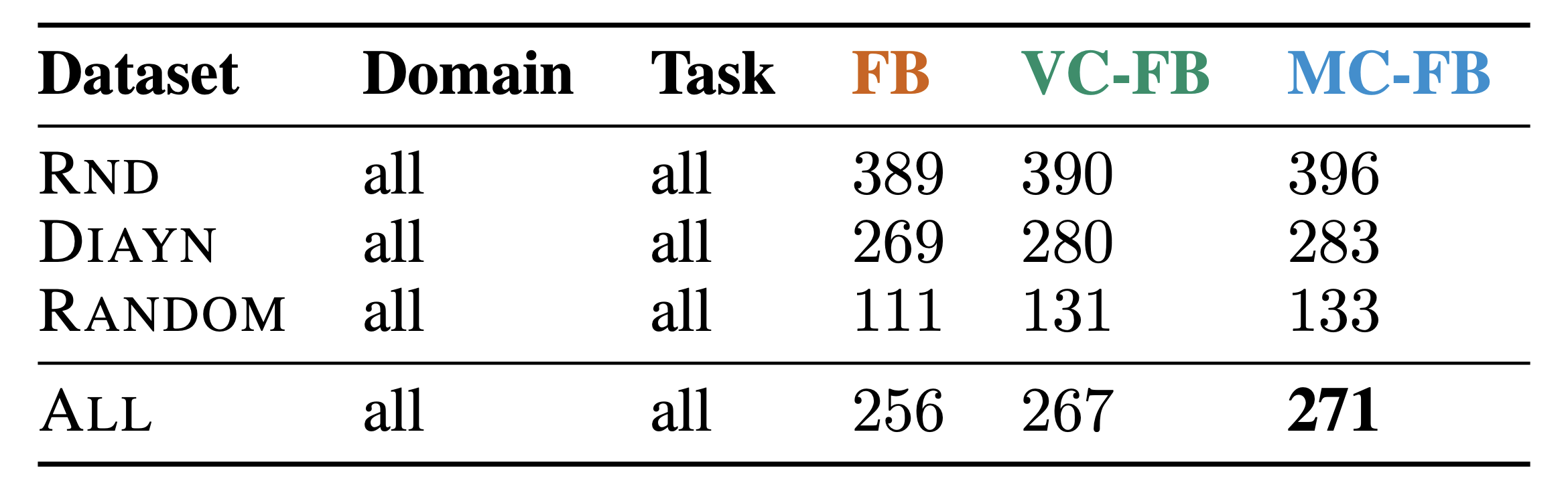
ExORL Results
Baselines
- Zero-shot RL: FB, SF-LAP [5]
- Goal-conditioned RL: GC-IQL [6]
- Offline RL: CQL [7]
Datasets

ExORL Results
D4RL Results
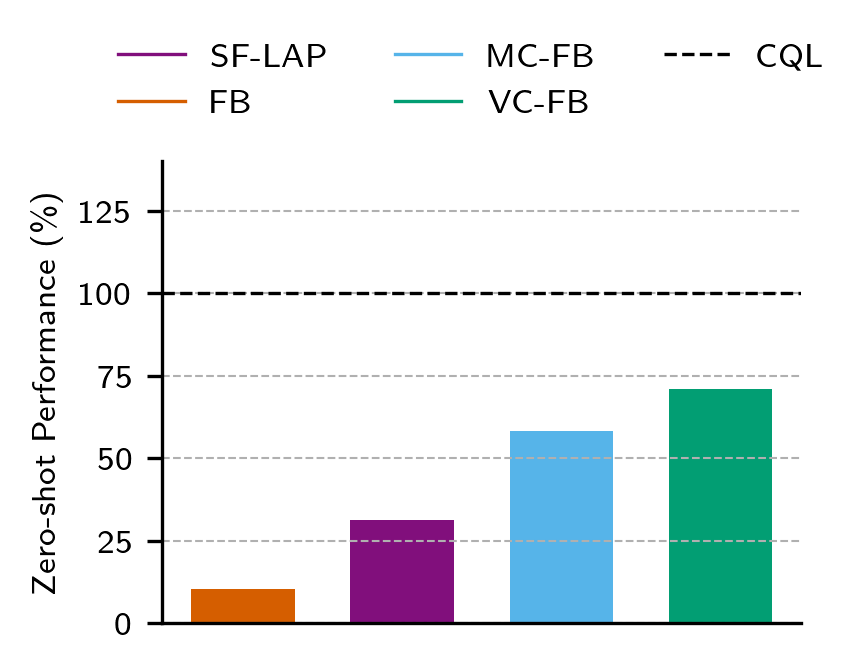
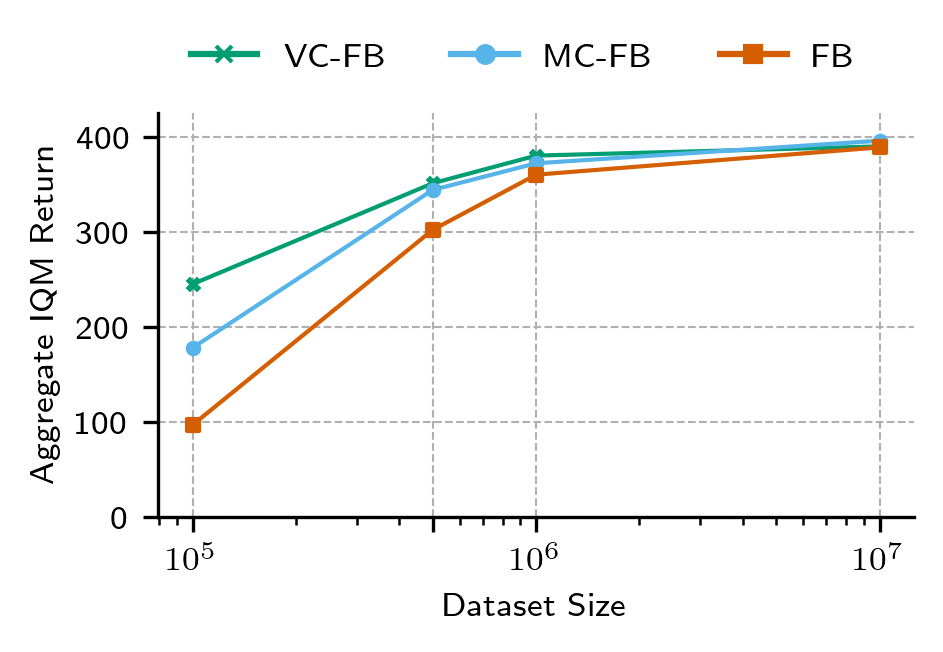
Performance on Idealised Datasets is Unaffected
Conclusions
- Like standard offline RL methods, BFMs suffer from the distribution shift
- As a resolution, we introduce Conservative BFMs
- Conservative BFMs considerably outperform standard BFMs on low-quality datasets
- Conservative BFMs do not compromise performance on idealised datasets
