Zero-Shot Reinforcement Learning from Low Quality Data
NeurIPS 2024
Scott Jeen\(^{1}\), Tom Bewley\(^{2}\), & Jonathan M. Cullen\(^{1}\)
\(^{1}\) University of Cambridge
\(^{2}\) University of Bristol
Summary

Figure 1: Conservative zero-shot RL methods.
Zero-shot reinforcement learning (RL) concerns itself with learning general policies that can solve any unseen task in an environment. Recently, methods leveraging successor features and successor measures have emerged as viable zero-shot RL candidates, returning near-optimal policies for many unseen tasks. However, to enable this, they have assumed access to unrealistically large and heterogeneous datasets of transitions for pre-training. Most real datasets, like historical logs created by existing control systems, are smaller and less diverse than these current methods expect. As a result, this paper asks:
Can we still perform zero-shot RL with small, homogeneous datasets?
Intuition

Figure 2: FB value overestimation with respect to dataset size \(n\) and quality.
When the dataset is inexhaustive, existing methods like FB representations overestimate the value of actions not in the dataset. The above shows this overestimation as dataset size and quality is varied. The smaller and less diverse the dataset, the more \(Q\) values tend to be overestimated.
We fix this by suppressing the predicted values (or measures) for actions not in the dataset, and show how this resolves overestimation in Figure 3–a modified version of Point-mass Maze from the ExORL benchmark. Episodes begin with a point-mass initialised in the upper left of the maze (⊚), and the agent is tasked with selecting \(x\) and \(y\) tilt directions such that the mass is moved towards one of two goal locations (⊛ and ⊛). The action space is two-dimensional and bounded in \([−1,1]\). We take the RND dataset and remove all “left” actions such that \(a_x \in [0, 1]\) and \(a_y \in [−1, 1]\), creating a dataset that has the necessary information for solving the tasks, but is inexhaustive (below (a)). We train FB and VC-FB on this dataset and plot the highest-reward trajectories–below (b) and (c). FB overestimates the value of OOD actions and cannot complete either task. Conversely, VC-FB synthesises the requisite information from the dataset and completes both tasks.

Figure 3: Ignoring out-of-distribution actions.
Aggregate Performance on Suboptimal Datasets

Figure 4: Aggregate zero-shot RL performance on ExORL benchmark.
Both MC-FB and VC-FB outperform FB and outperform our single-task baseline in expectation, reaching 111% and 120% of CQL performance respectively despite not having access to task-specific reward labels and needing to fit policies for all tasks. This is a surprising result, and to the best of our knowledge, the first time a multi-task offline agent has been shown to outperform a single-task analogue.
Performance with respect to dataset size

Figure 5: Performance by RND dataset size.
The performance gap between conservative FB variants and vanilla FB increases as dataset size decreases. On the full datasets, conservative FB variants maintain (and slightly exceed) the performance of vanilla FB.
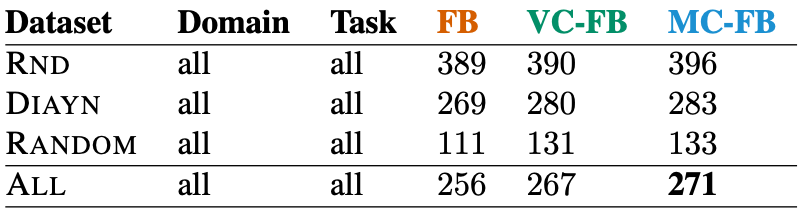
Table 1: Performance on full datasets.
Citation
Read the full paper for more details: [link], and if you find this work informative please consider citing it:
@article{jeen2023,
url = {https://arxiv.org/abs/2309.15178},
author = {Jeen, Scott and Bewley, Tom and Cullen, Jonathan M.},
title = {Conservative World Models},
publisher = {arXiv},
year = {2023},
}
eaec898 @ 2024-06-14