9 minutes
NeurIPS 2022
I was fortunate to attend NeurIPS in New Orleans in November. Here, I publish my takeaways to give you a feel for the zeitgeist. I’ll discuss, firstly, the papers, then the workshops, and finally, and briefly, the keynotes.
Papers
Here’s a ranked list of my top 8 papers. Most are on Offline RL, which is representative of the conference writ large.
1. Does Zero-Shot Reinforcement Learning Exist (Touati et. al, 2022)
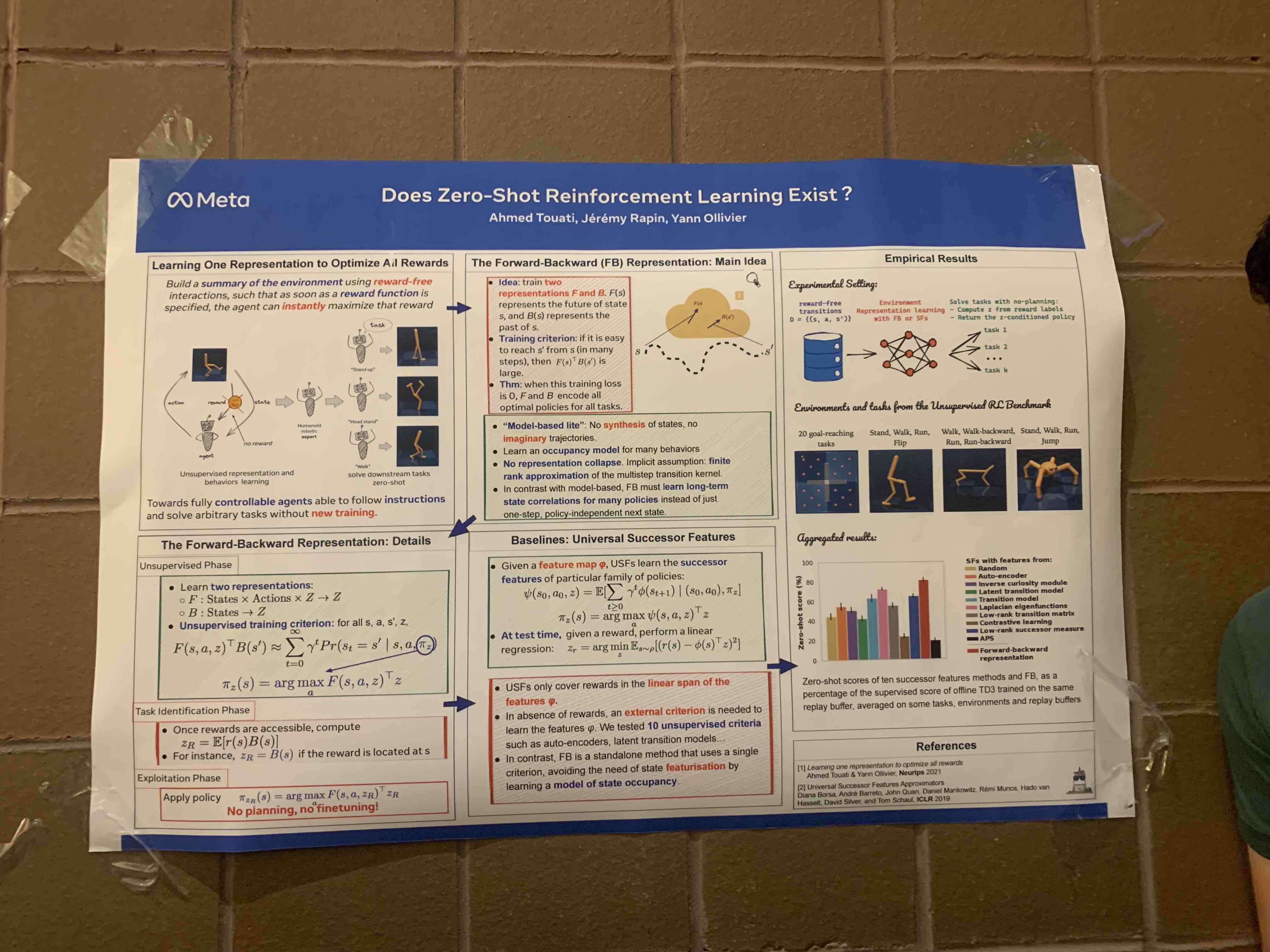
Key idea. To do zero-shot RL, we need to learn a general function from reward-free transitions that implicitly encodes the trajectories of all optimal policies for all tasks. The authors propose to learn two functions: \(F_\theta(s)\) and \(B_\phi(s)\) that encode the future and past of state \(s\). We want to learn functions that always find a route from \(s \rightarrow s'\).
Implication(s):
- They beat all previous zero-shot RL algorithms on the standard offline RL tasks, and approach the performance of online, reward-guided RL algorithms in some envs.
Misc thoughts:
- It seems clear that zero-shot RL is the route to real world deployment for RL. This work represents the best effort I’ve seen in this direction. I’m really excited by it and will be looking to extend it in my own future work.
2. Large Scale Retrieval for Reinforcement Learning (Humphreys et. al, 2022)
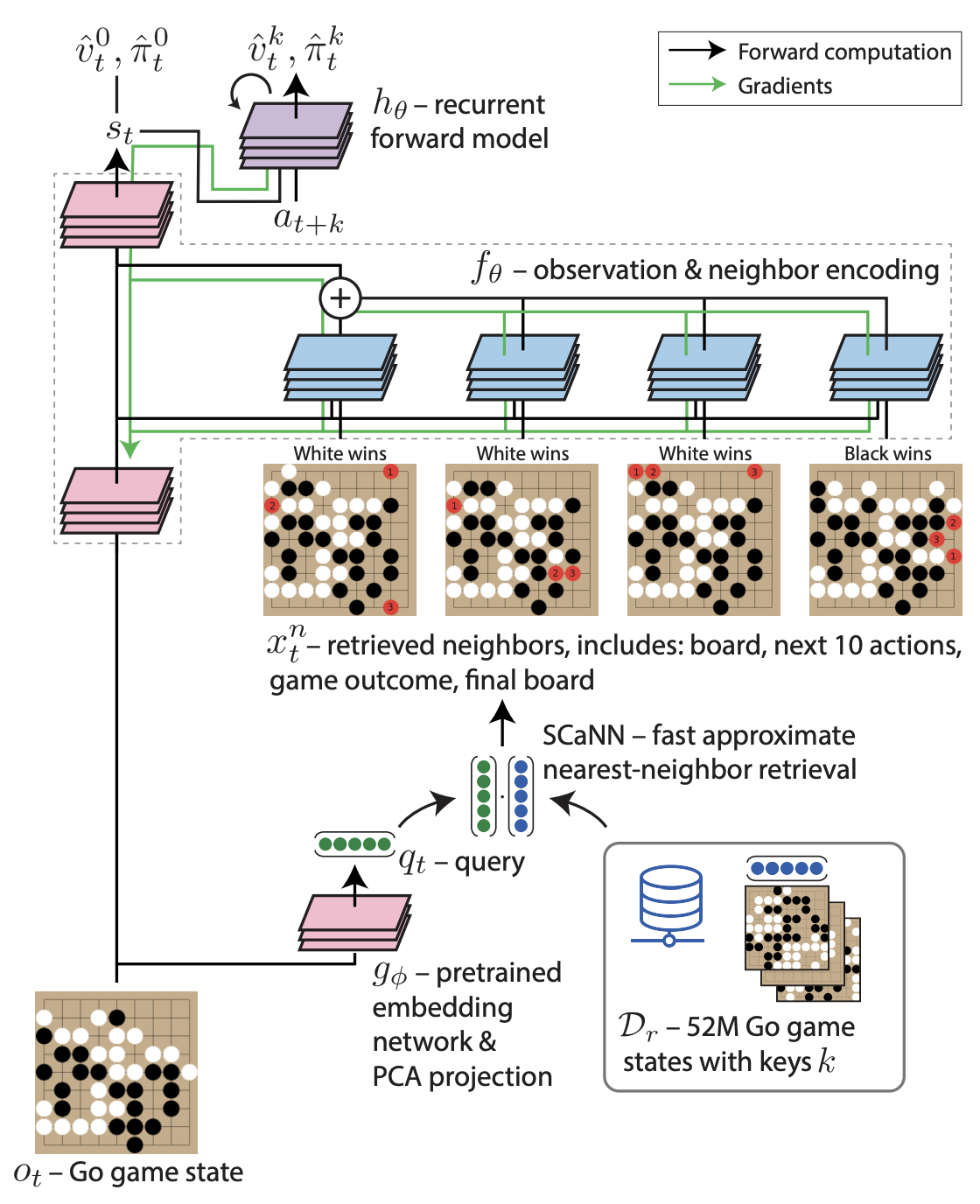
Key idea. Assuming access to a large offline dataset, we perform a nearest neighbours search over the dataset w.r.t. the current state, and append the retrieved states, next actions, rewards and final states (in the case of go) to the current state. The policy then acts w.r.t this augmented state.
Implication(s):
- Halves compute required to achieve the baseline win-rate in Go.
Misc thoughts:
- This represents the most novel approach to offline RL I’ve seen; most techniques separate the offline and online learning phases, but here the authors combine them elegantly.
- To me this feels like a far more promising approach to offline RL than CQL etc.
3. The Phenomenon of Policy Churn (Schaul et. al, 2022)


Key idea. When a value-based agent acts greedily, the policy updates by a surprising amount per gradient step e.g. in up to 10% of states in some cases.
Implication(s):
- Policy churn means that ((\epsilon))-greedy exploration may not be required as a rapidly changing policy induces enough noise into the data distribution that exploration may be implicit.
Misc thoughts:
- Their paper is structured in a really engaging way.
- I liked their ML researcher survey which quantified how surprising their result was to experts.
4. MINEDOJO: Building Open-Ended Embodied Agents with Internet-Scale Knowledge (Fan et. al, 2022)
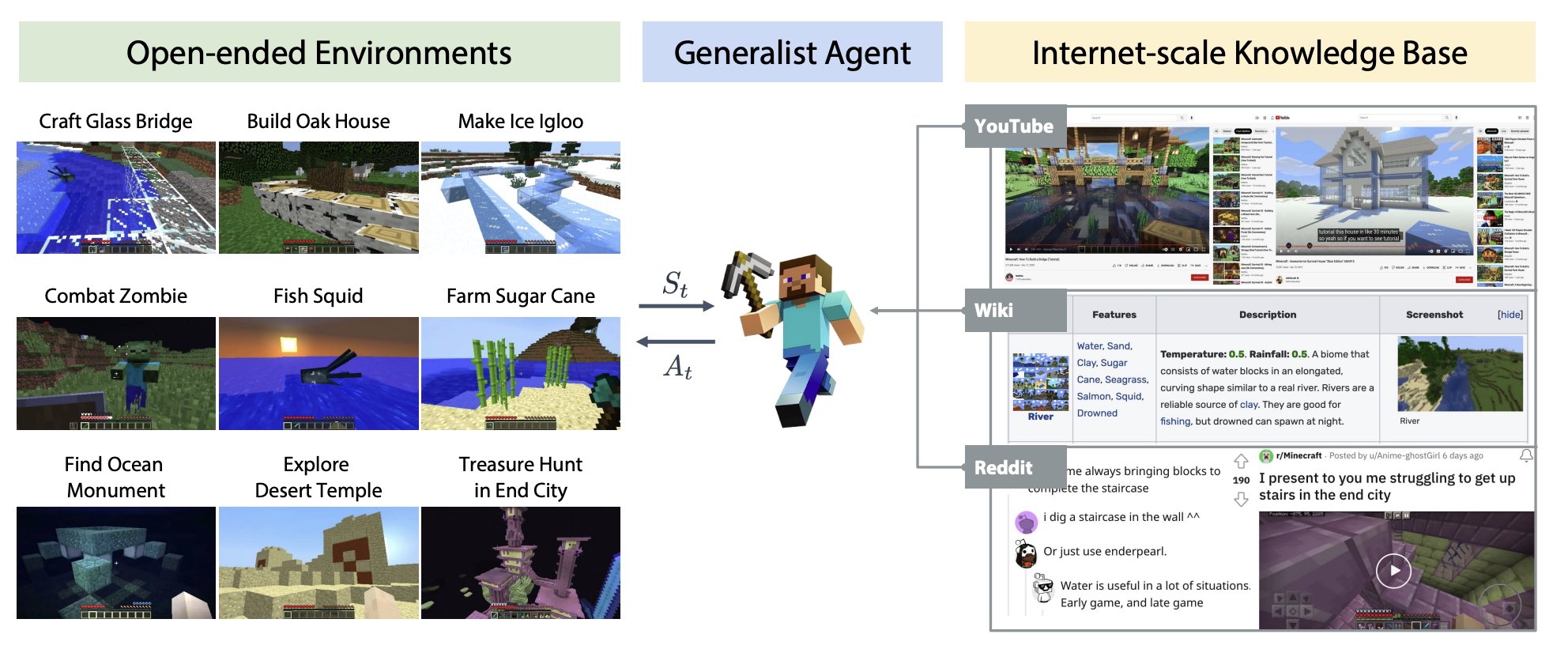
Key idea. An internet-scale benchmark for generalist RL agents. 1000s of tasks, and a limitless procedurally-generated world for training.
Implication(s):
- Provides a sufficiently diverse and complex sandbox for training more generally capable agents.
Misc thoughts:
- This is an amazing feat software development effort from a relatively small team. Jim Fan is so cool!
5. Exploration via Elliptical Episodic Bonuses (Henaff et. al, 2022)
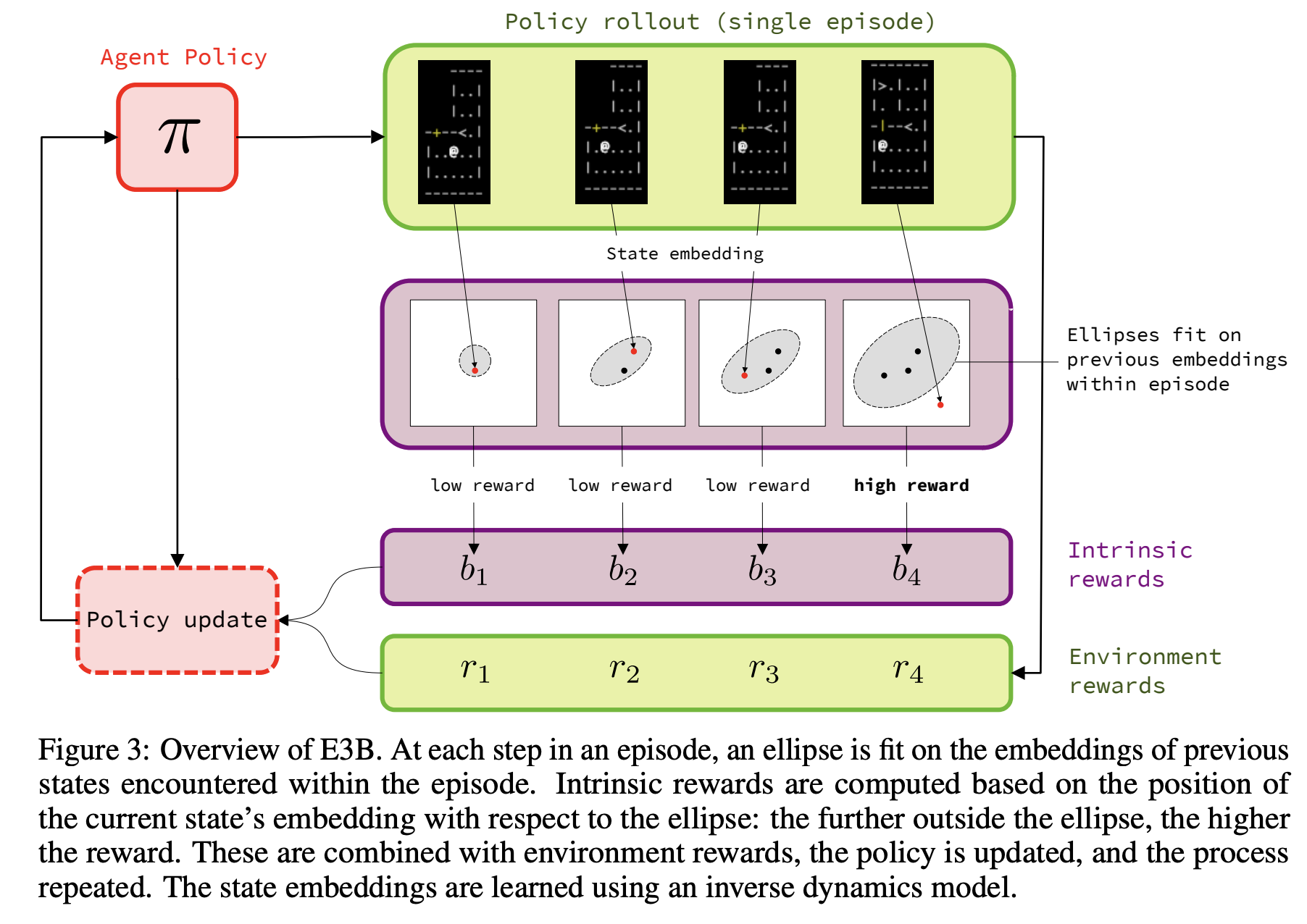
Key Idea. Guided exploration is often performed by providing the agent reward inversely proportional to the state visitation count i.e. if you haven’t visited this state much you receive added reward. This works for discrete state spaces, but in continuous state spaces each visited state is ~ unique. Here, the authors parameterise ellipses around visited states, specifying a region of nearby states, outside of which the agent receives added reward.
Implication(s):
- Better exploration means SOTA on the mini-hack suite of envs
- Strong performance of reward-free exploration tasks i.e. this is a really good way of thinking about exploration.
Misc. thoughts:
- I really liked the elegance of this idea. A good example of simple, well-examined ideas being useful to the community.
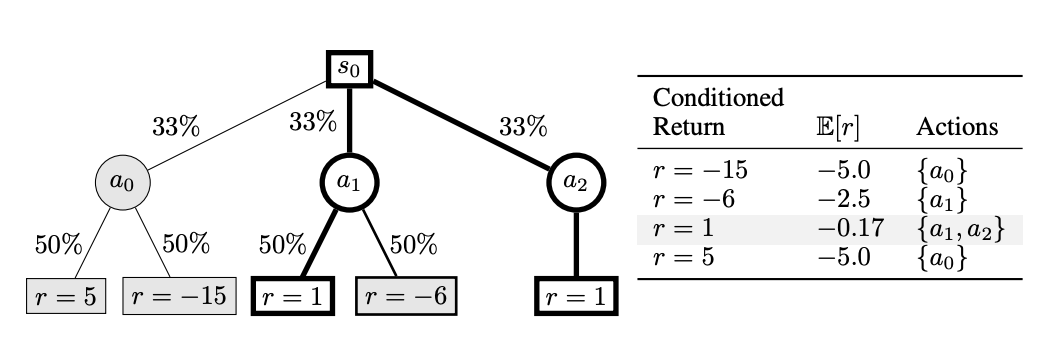
Key Idea. In a stochastic environment, trajectories in a dataset used to train decision transformer may be high-reward by chance. Here the authors cluster similar trajectories and find their expected reward to mitigate overfitting to lucky trajectories.
Implication(s):
- Decision transformer trained on these new objectives exhibits policies that area better aligned with the return conditioning of the user.
Misc. thoughts:
- Another simple idea with positive implications for performance.
7. Multi-Game Decision Transformers (Lee et al., 2022)
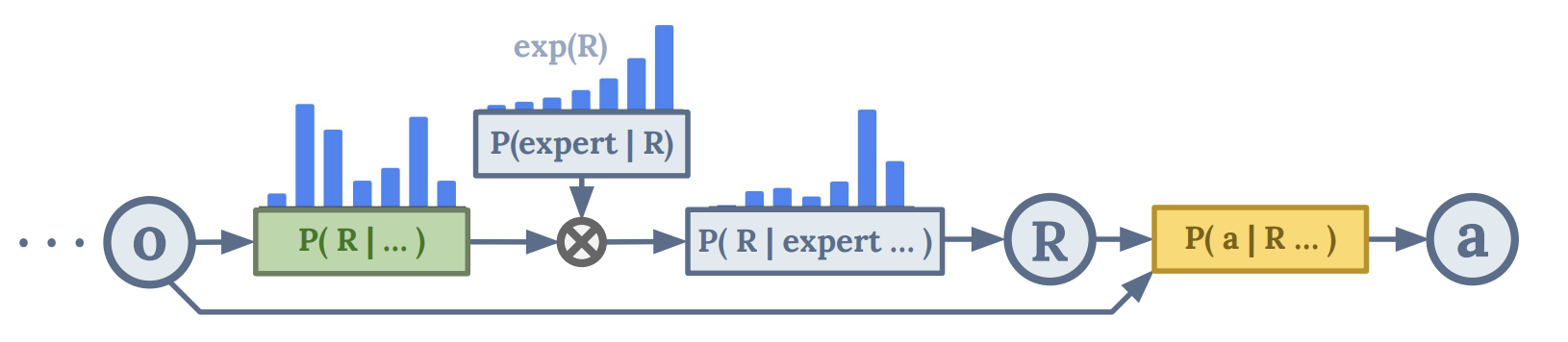
Key idea. Instead of predicting just the next action conditioned on state and return-to-go like the original decision transformer paper, they predict the intermediate reward and return-to-go. This allows them to re-condition on new returns-to-go at each timestep, using a clever sampling procedure that samples likely expert returns-to-go.
Implication(s):
- SOTA on standard atari offline RL tasks.
Misc thoughts:
- This work is very similar to the original decision transformer paper, so I’m surprised that it received a best paper award.
- It represents continued progress in the field on offline RL, and more specifically, decision transformer style architectures.
Key idea. Much recent work on offline RL can be cast as supervised learning on a near-optimal offline dataset then conditioning on high rewards from the dataset at test time; under what conditions is this a valid approach? Here the authors prove that this (unsurprisingly) only works when two conditions are met: 1) the test envs are (nearly) deterministic, and 2) there is trajectory-level converage in the dataset.
Implication(s):
- Current approaches to offline RL will not work in the real world because real envs are generally stochastic.
Misc thoughts:
- I liked that the authors proved the community’s intuitions on current approaches to offline RL that, although somewhat obvious in retrospect, had not been verified.
Workshops
I attended 5 workshops:
- Foundation Models for Decision Making
- Safety
- Offline RL
- Real Life Reinforcement Learning
- Tackling Climate Change with Machine Learning
I found the latter three to be interesting, but less informative and precient as the first two. I therefore only discuss the Foundation Models for Decision Making and Safety workshops; the extent to which I enjoyed both workshops is, in a sense, oxymoronic.
Foundation Models for Decision Making
Leslie P. Kaelbling: What does an intelligent robot need to know?
My favourite talk was from Leslie Kaelbling of MIT. Kaelbling focussed on our proclivity for building inductive biases into our models (a similar thesis to Sutton’s Bitter Lesson); though good in short term, the effectiveness of such priors plateaus in the long-run. I agree with her.
She advocates for a marketplace of pre-trained models of the following types:
- Foundation: space, geometry, kinematics
- Psychology: other agents, beliefs, desires etc.
- Culture: how do u do things in the world e.g. stuff you can read in books
Robotics manufacturers will provide:
- observation / perception
- actuators
- controllers e.g. policies
And we’ll use our own expertise to build local states (specific facts about the env) and encode long horizon memories e.g. what did I do 2 years ago.
Safety (unofficial; in the Marriott across the road)
The safety workshop was wild. It was a small, unofficial congregation of researchers who you’d expect to see lurking on Less Wrong and other EA forums.
Christoph Schuhmann (Founder of LAION)
Chris is a high school teacher from Vienna; he gave an inspiring talk on the open-sourcing of foundation models. He started LAION (Large-scale Artificial Intelligence Open Network) a non-profit organization, provides datasets, tools and models to democratise ML research. His key points included:
- centralised intelligence means centralised problem solving; we can’t give the keys to problem solving to a (potentially) dictatorial few.
- risks by not open sourcing AI are bigger than those of open sourcing
- LAION progress:
- initial plan was to replicate the orignal CLIP / Dalle-1
- got 3m image text pairs on his own
- discord server helped him get 300m image text pairs, then 5b pairs
- hedge fund gave them 8 A100s
- We will always want to do things even if AI can, cause we need to express ourselve
Thomas Wolf (Hugging Face CEO)
Tom Wolf gave a talk on the Big Science initiative, a project takes inspiration from scientific creation schemes such as CERN and the LHC, in which open scientific collaborations facilitate the creation of large-scale artefacts that are useful for the entire research community:
- 1000+ researchers coming together to build massive language model and massive dataset
- efficient agi will probs require modularity cc. LeCun
- working on the energy efficiency of training is inherently democratic i.e. stops models being held by the rich, especially re: inference
Are AI researchers aligned on AGI alignment?
There was interesting round table at the end of the workshop that included Jared Kaplan (Anthropic) and David Krueger (Cambridge) discussing what is means to align AGI. There was little agreement.
Keynotes
I attended 4 of the 6 keynotes which were:
- David Chalmers: Are Large Language Models Sentient?
- Emmanuel Candes: Conformal Prediction in 2022
- Isabelle Guyon: The Data-Centric Era: How ML is Becoming an Experimental Science
- Geoff Hinton: The Forward-Forward Algorithm for Training Deep Neural Networks
I found Emmanuel’s talk on conformal prediction enlightening as I’d never heard of the topic (here’s a primer), and Isabelle’s talk on benchmark and data transparency to be agreeable, if a little unoriginal. Hinton’s talk on a more anatomically correct learning algorithm was interesting, but I’m as yet unconvinced that mimicking human intelligence is a good way of building systems that are superior to humans—we are able to leverage hardware for artificial systems far superior to that accessible to humans. Chalmers talk was extremely thought-provoking; he structured the problem of consciousness in LLMs excellently—far better than I’ve seen to date, and as such was my favourite of the four.
I have linked to each of the talks, which are freely available to view above.
References
Fan, L.; Wang, G.; Jiang, Y.; Mandlekar, A.; Yang, Y.; Zhu, H.; Tang, A.; Huang, D.-A.; Zhu, Y.; and Anandkumar, A. 2022. Minedojo: Building open-ended embodied agents with
internet-scale knowledge. Advances in neural information processing systems, 35.
Henaff, M.; Raileanu, R.; Jiang, M.; and Rockt ̈aschel, T. 2022. Exploration via Elliptical Episodic Bonuses. Advances in neural information processing systems, 35.
Humphreys, P. C.; Guez, A.; Tieleman, O.; Sifre, L.; Weber, T.; and Lillicrap, T. 2022. Large-Scale Retrieval for Reinforcement Learning. Advances in neural information processing systems, 35.
Lee, K.-H.; Nachum, O.; Yang, M.; Lee, L.; Freeman, D.; Xu, W.; Guadarrama, S.; Fischer, I.; Jang, E.; Michalewski, H.; et al. 2022. Multi-game decision transformers. Advances in neural information processing systems, 35.
Paster, K.; McIlraith, S.; and Ba, J. 2022. You Can’t Count on Luck: Why Decision Transformers Fail in Stochastic Environments. Advances in neural information processing systems, 35.
Schaul, T.; Barreto, A.; Quan, J.; and Ostrovski, G. 2022. The phenomenon of policy churn. Advances in neural information processing systems, 35.
Touati, A.; Rapin, J.; and Ollivier, Y. 2022. Does Zero-Shot Reinforcement Learning Exist?