Taking a peek inside black-box function approximators
Xchange Seminar, Cambridge
15th March 2021, 1pm
Abstract
In this talk, I will introduce deterministic and probabilistic black-box function approximators, with applications for timeseries modelling. First, I introduce the multilayer perceptron (neural network), demonstrating how they can model arbitrarily complex functions, but highlighting their propensity to overfit the training data. Second, I introduce the Gaussian process (GP), a bayesian, probabilistic approach to function approximation. I visualise how GP’s quantify uncertainty, a robust trait in the context of control, but highlight their inability to scale to large datasets. I conclude by applying both techniques to the problem of room temperature prediction.
Code
![]()
Slides
Today’s Talk
- My project
- Black-box function approximation
- Deterministic approach: Neural networks and Long-short term memory (LSTMs)
- Probabilistic approach: Gaussian processes (GPs)
- Timeseries applications
- Key takeaways
My Project
Let’s start with a video of one of DeepMind’s machine learning agents learning to play the Atari game Breakout [1]. DeepMind feed the agent three pieces of information: 1) The pixel arrangement of the screen, 2) The actions it can take i.e. that can move left or right only, and 3) the score. The task of the agent is to learn to maximise its score by any means necessary. You’ll note that, initially, the agent doesn’t understand how best to play the game, but after more iterations it begins to get the hang of it. After 600 episodes of play, the agent has worked out the optimal strategy for this game: burrow a channel in either side of the bricks and fire the ball into the space behind.
1. My Project

Video: Deepmind’s Deep Q-network solving the Atari game Breakout after 600 episodes of self-play (Mnih et. al (2013))
A couple of years later, DeepMind took things a step further and attempted to conquer Go–a considerably more complex game [2]. Now, we’re moving from a relatively straight forward state-space to a state-space with $~10^{170}$ legal positions, far more atoms that in the observable universe.
DeepMind created a more advanced agent, AlphaGo, and used it to play the world no. 1 Lee Sedol in best of 5 match, winning 4-1. Perhaps the most interesting takeaway from the series was AlphaGo’s now infamous move 37 (see this clip from DeepMind’s documentary). Expert Go players suggest that in the board setup illustrated below, human Go players have long believed that the optimal move is in the margins of the board, but AlphaGo decided to play 5 lines in from the edge; much to the surprise of the audience, and Lee Sedol. This move later proved to be game-winning; AlphaGo had correctly predicted how the board would evolve and that move scuppered its opponent. After a few weeks of training, AlphaGo unearthed knowledge about this game that humans hadn’t found after thousands of years of play.
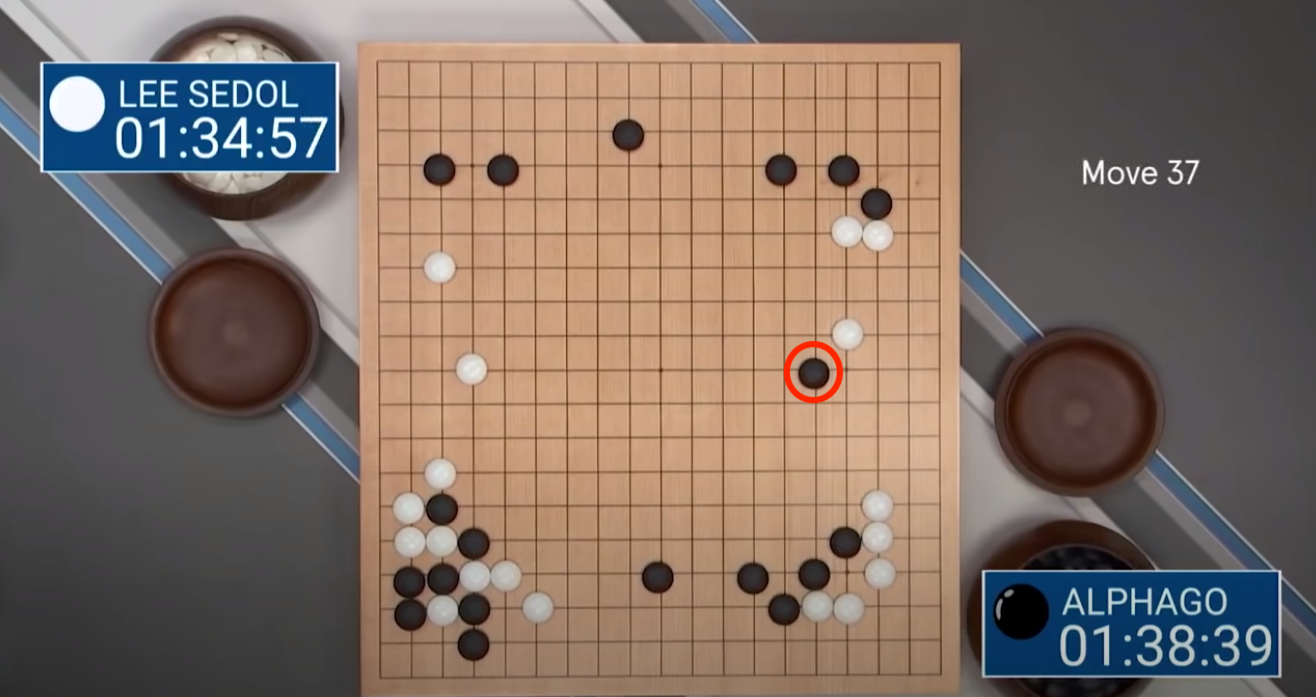

Figure: Top: AlphaGo’s infamous Move 37, a counterintuitive move for a human to make with this board set-up, but nonetheless a gaming-winning one. Bottom: Lee Sedol, the world no.1 Go player, flummoxed by AlphaGo’s moves. (Silver et. al(2017))
So, why am I telling you this? Well, for my PhD project, I think instead of playing Atari games we should play the game of climate change mitigation. Specifically, let’s turn the electricity system into a game. The board is the electricity grid, our pieces are energy-intensive devices on the grid, and our goal is to minimise the emissions produced by these devices whilst maintaining a quality of service to society.

Figure: The complex, interconnected electricity grid
As a first step in this direction, my goal is to control one building such that it interacts with the grid most efficiently, and we’re doing that in one of Emerson Electric’s facilities out in Canada, but more on that later.
1.1 Reinforcement Learning
I haven’t yet discussed the technique DeepMind used to produce these results; its called Reinforcement Learning [3]. In general, the RL control loop looks something like this:

Figure: The RL control loop. Agent’s take sequential actions that affect their environment, the environment changes and the agent receives a reward for their action. Adapted from Episode 1 of David Silver’s RL Youtube series
The brain here represents the agent, the globe represents its environment. The agent can take actions in the environment, after which the environment feeds it some reward and tells it what the new state is. The agent’s goal is maximise its cumulative reward, i.e. find the set of actions given states that win the game or meet its control objective.
More formally, the RL control loop looks something like this:
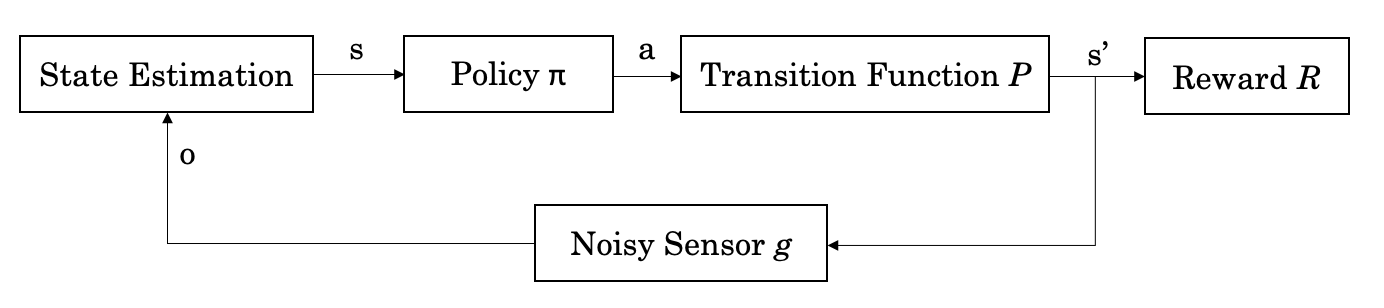
Figure: The formalised RL control loop.
Where the agent observes the state $s$ through some sensor that is often noisy, it feeds the state into its control policy which selects an action $a$ given $s$, sending the agent through a transition represented by $P$ to new state $s'$. This transition, often called the system dynamics, can be modelled as a black box function. I’m going to spend the rest of this walkthrough discussing how the ways in which you can approximate a function using black methods, when we should do so, and the limitations of doing so.
2. Black-box Function Approximation
2.1 Two approaches to modelling
Generally when we model a function using a black-box approximator, we can select (informally) from two sets of models, these are:
- Deterministic models: Do not contain elements of randomness; every time the model is run with the same initial conditions it produces identical results.
- Probabilistic models: Include elements of randomness; trials with identical initial conditions will produce different results.
As you can imagine, these are philosophically contradictory ways of thinking about modelling. The first assumes that there is a definite underlying function to be modelled, and with enough data we will be able to obtain it with sufficient accuracy. The second, assumes the world is random, we will never find the true underlying function because every function is subject to irreducible randomness or uncertainty in the world (cf. aleatoric uncertainty). The two eminent modelling techniques in these camps are Neural Networks (deterministic) and Gaussian Processes (probabilistic). I’ll run through an example explaining the differences between the two.
2.2 Deterministic Models: Neural Networks
Firstly, we need some data. Let’s imagine we’ve collected 5 samples from the world that were produced by a function we’d like to infer. For simplicity, we’ll assume this model is one-dimensional with inputs $x_i$ and outputs $y_i$ creating a dataset of input-output pairs $\mathrm{D} = {x_i,y_i}_i^N$ where we assume the relationship between the variables is $y_i = f(x_i)$. Our goal is to infer the function $f(\cdot)$ from $\mathrm{D}$:

In the first instance, let’s think about modelling this data deterministically. We might think that there is a linear relationship in the underlying data, so we model it as a straight line and manipulate the parameters of our straight line until the error between our line and the data in minimised. Our linear model takes the form:
Linear Basis
$$ f(x) = {\color{red}{w_0}} + {\color{blue}{w_1} x} $$

We can set the parameters of our linear model such that the error is pretty small, but we also know that the underlying function is unlikely to be a truly linear. Instead, we could improve on this by assuming our basis function is no longer linear, but rather polynomial, taking the form:
Polynomial Basis
$$ f(x) = {\color{red}{w_0}} + {\color{blue}{w_1}} x + {\color{green}{w_2}} x^2 + {\color{orange}{w_3}} x^3 $$

With enough manipulation, we could probably find a set of parameters for our polynomial that approximate that dataset pretty closely.
Neural networks take this approach to the extreme. We’ve looked at two basis functions so far, the linear model and the polynomial, for efficient computation neural networks tend to use the Rectified Linear Unit (ReLU) basis function, usually called the network’s activation function for reasons that will become clear shortly.
ReLUs take the following form:
Rectified Linear Unit (ReLU)
$$ f(x) = \max (0 , {\color{blue}{w_1}} x + {\color{red}{w_0}}) $$
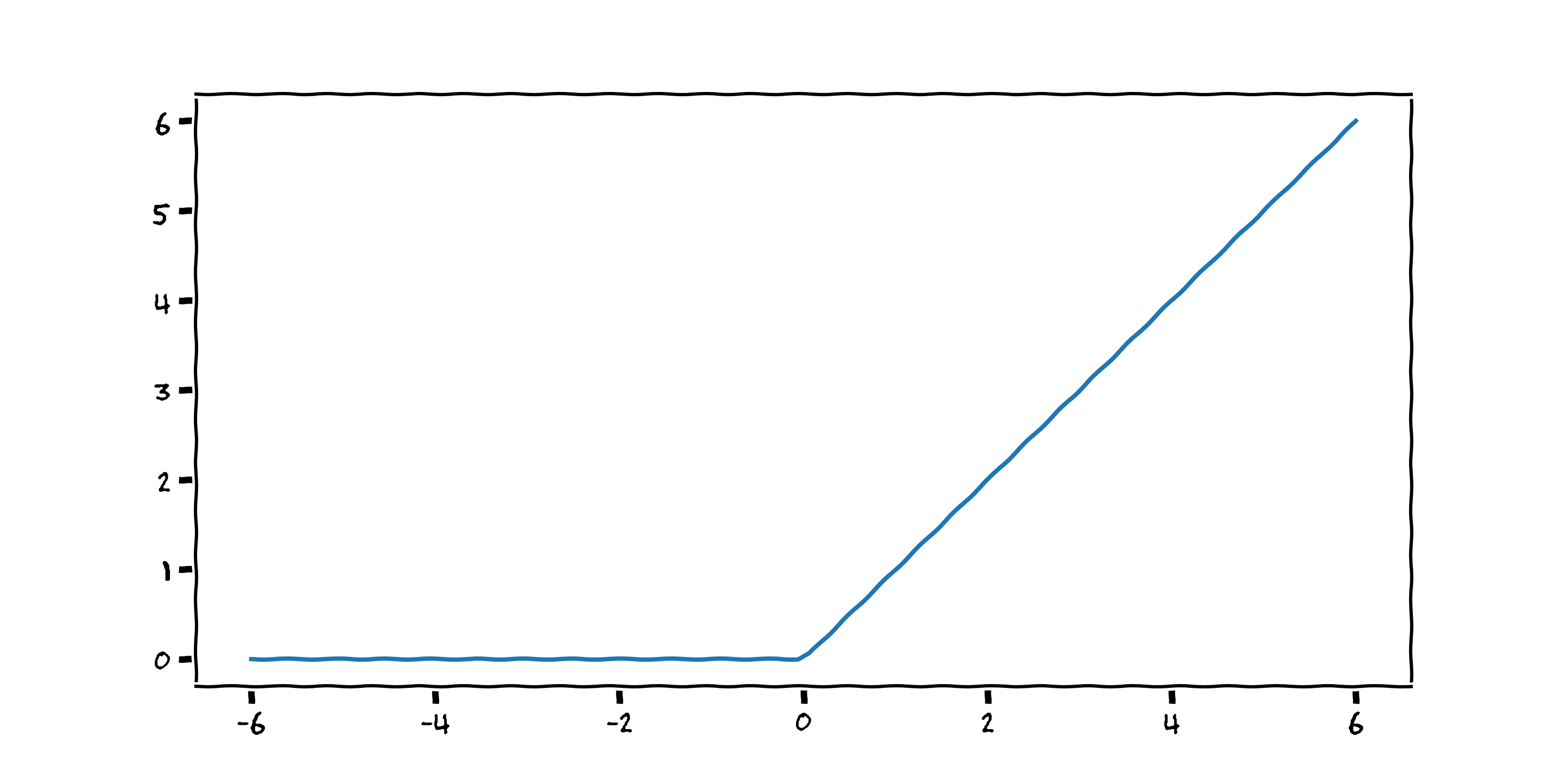
They are named activation functions because they activate the output for a certain input. Neural networks are a linear combination of these activation functions, the output of which can, surprisingly, model any continuous function (cf. the universal function approximator theorem). Inspired by this great blog post from Brendan Fortuner, I tried to model our dataset using four ReLUs:
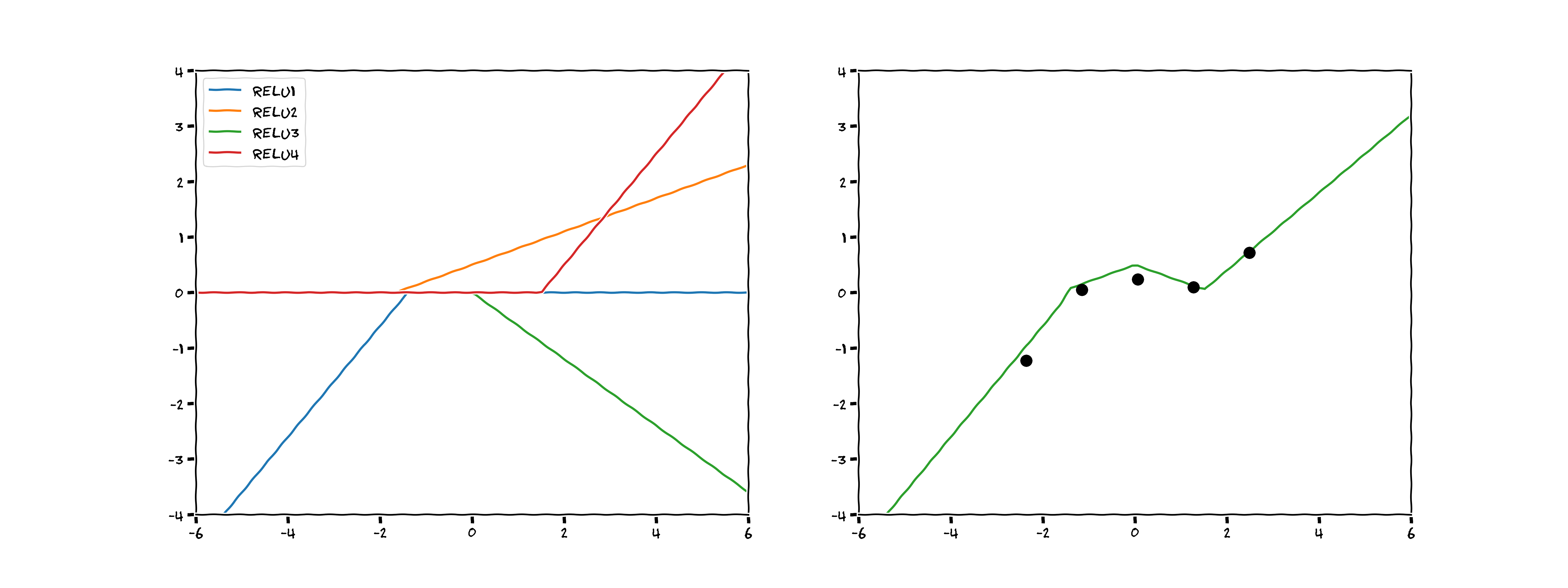
Not a bad estimation! On the left you can see when each of the four ReLUs activate, and how they affect the function once activated. On the right, you can see the sum of those four activations.
In effect, we have created a neural network with four nodes by hand (see the top graph in the image below). You can imagine that with more ReLUs we could produce a smoother fit to the data, 2 sets of 10 ReLUs would look something like the bottom graph in the image below:


Figure: Top: A neural network with 4 nodes and 1 hidden layer–a graph of the model created by hand above. Bottom: A neural network with 10 nodes and 2 hidden layers–a more typical model arrangement.
Now we’ll pass our dataset through a neural network of 30 nodes (node number picked arbitrarily), optimise and make predictions of the output. Here’s what we get:

That looks even better! The function smoothly fits the data in a way that looks quite probable. Let’s see how our model compares to the true function:

Ah. Things have gone awry. The neural network has completely mischaracterised the underlying function. We can forgive the neural network for getting it so wrong, but it would have been great if it had told us it wasn’t sure! The neural network is arrogant, it thinks there is only one function that could have produced the data and that it’s nailed it after seeing five datapoints. It cannot possibly know how the function behaves when $x < -4$ or when $x > 4$ yet it still makes confident assertions about $y$ there. Ideally, we’d like an approach that tells us when it is confident in its predictions and when it is less confident. To do so, we’ll now turn to the probabilistic approach.
3. Probabilistic Models: Gaussian Processes
We know that there are an infinite number of functions that could have produced the data we observe, and that we’ll never be able to say for certain which one of these infinite functions is correct, but we’d like to know which subset of these functions is most probable. The question becomes: how can we narrow our solution space from every possible function to a subset that could have feasibly produced the data we observe.
We use Bayes' rule to narrow the solution space, which tells us how to update our beliefs about the world based on the evidence we’ve seen:
$$ P (A | B) = \frac{P(B | A) P(A)}{P(B)} $$
and in the setting of functions and data it looks something like:
$$ P (\textbf{f} | \textbf{D}) = \frac{P(\textbf{D} | \textbf{f}) P(\textbf{f})}{P(\textbf{D})} $$
The latter provides a predictive posterior distribution over the function space given the data we have observed i.e. of the infinite set of functions available to us, which are the most likely given the data. I’m going to focus first on the prior $P(\textbf{f})$, which is where we as modellers can input our beliefs about the world prior to seeing any data. Let’s return to our original dataset and think about our prior beliefs:
We may think that the functions are likely to be quite smooth. Perhaps we know that the data has been sampled from a process that changes state slowly and smoothly e.g. the tide height in a harbour throughout a day. Here are 20 functions sampled from the infinite set of smooth functions produced by the Radial Basis Function.
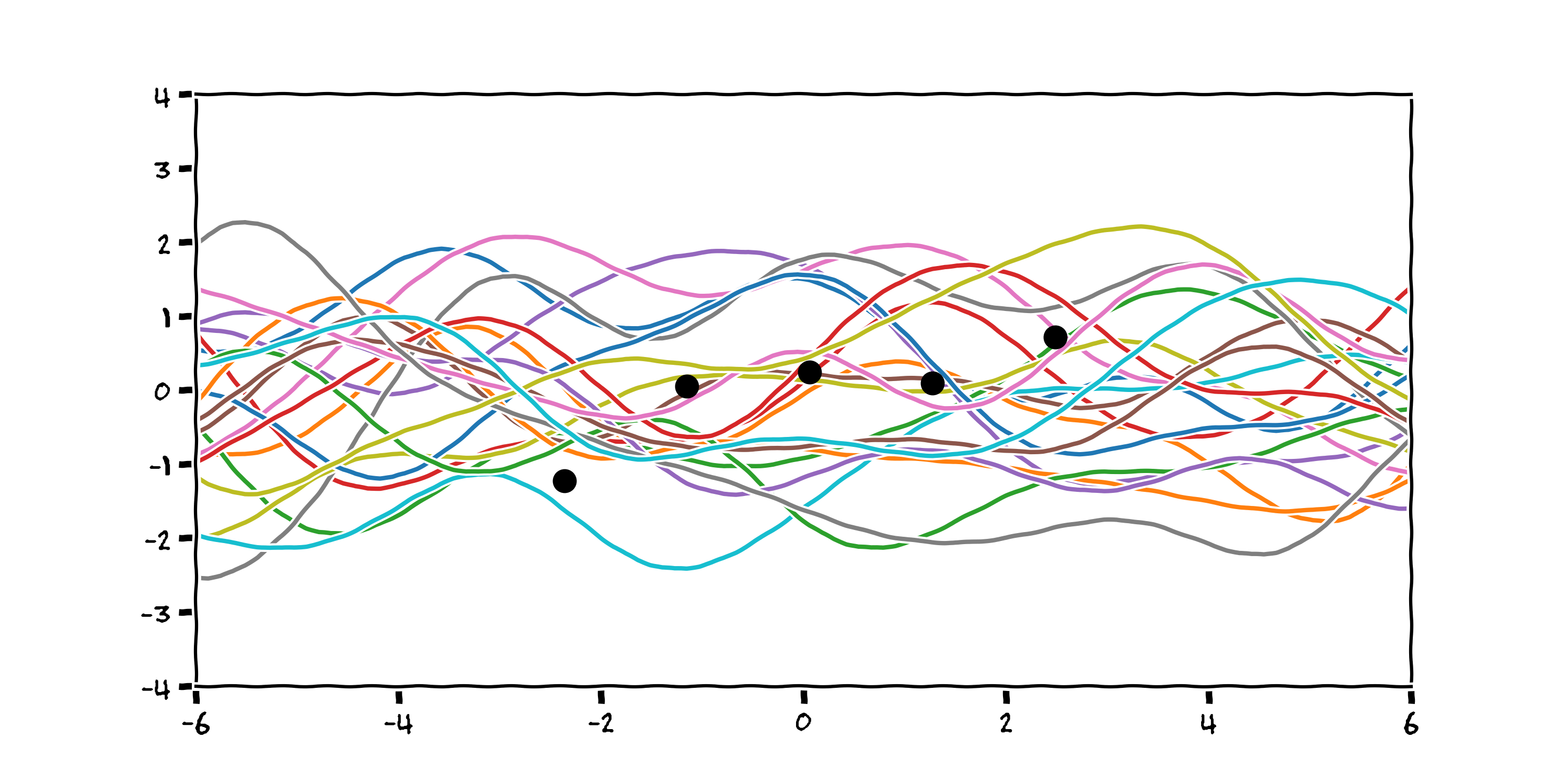
Or we might think the process isn’t quite so smooth and perhaps varies more stochastically. Here are 20 functions sampled using a periodic basis function:

From this prior, we can reject each function from the infinite set that does not pass through our datapoints by optimising the log marginal likelihood of the functions (a description of which is outside the scope of this talk).
If we return to our Radial Basis Function kernel, reject all the functions that don’t pass through our datapoints, plot 1000 of the remaining functions we get something that looks like this:

Now we have a plot that accepts there are many reasonable explanations for the data we observe. We can then take the mean and standard deviation of the distribution of these function and create a plot with confidence intervals:
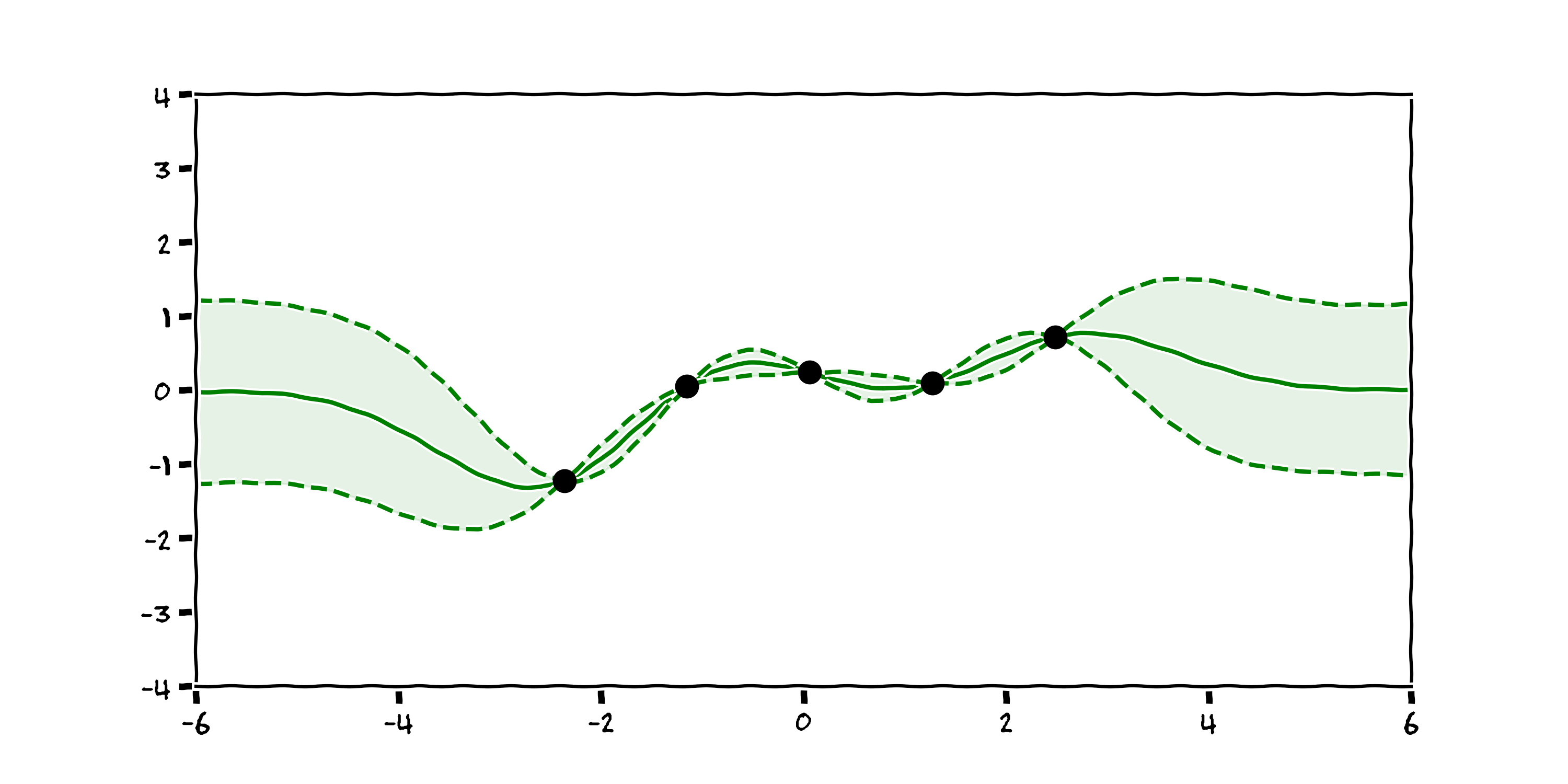
Now the black box is telling where it is more and less confident. In the context of control, or reinforcement learning, this is more robust as the agent can be wary when there is uncertainty in the state of the system. This modelling technique is called a Gaussian Process [4].
3.3 Drawbacks
- Expensive to compute; N > ~50,000 prohibitively large
- Prior knowledge remains crucial
4. Timeseries applications
Many of the problems we tackle in our group can be described as timeseries, that is, the inputs and outputs of the system are indexed by time. Examples include: the flow of material through a manufacturing plant, CO2 air concentration, or daily energy generation from a solar panel. In such scenarios, we can take advantage of the sequential nature of the output to inform our model.
By way of example, I’m going to use the two techniques discussed thus far to predict the time-varying temperature in a coldstorage facility. Let’s have a look at the data first:
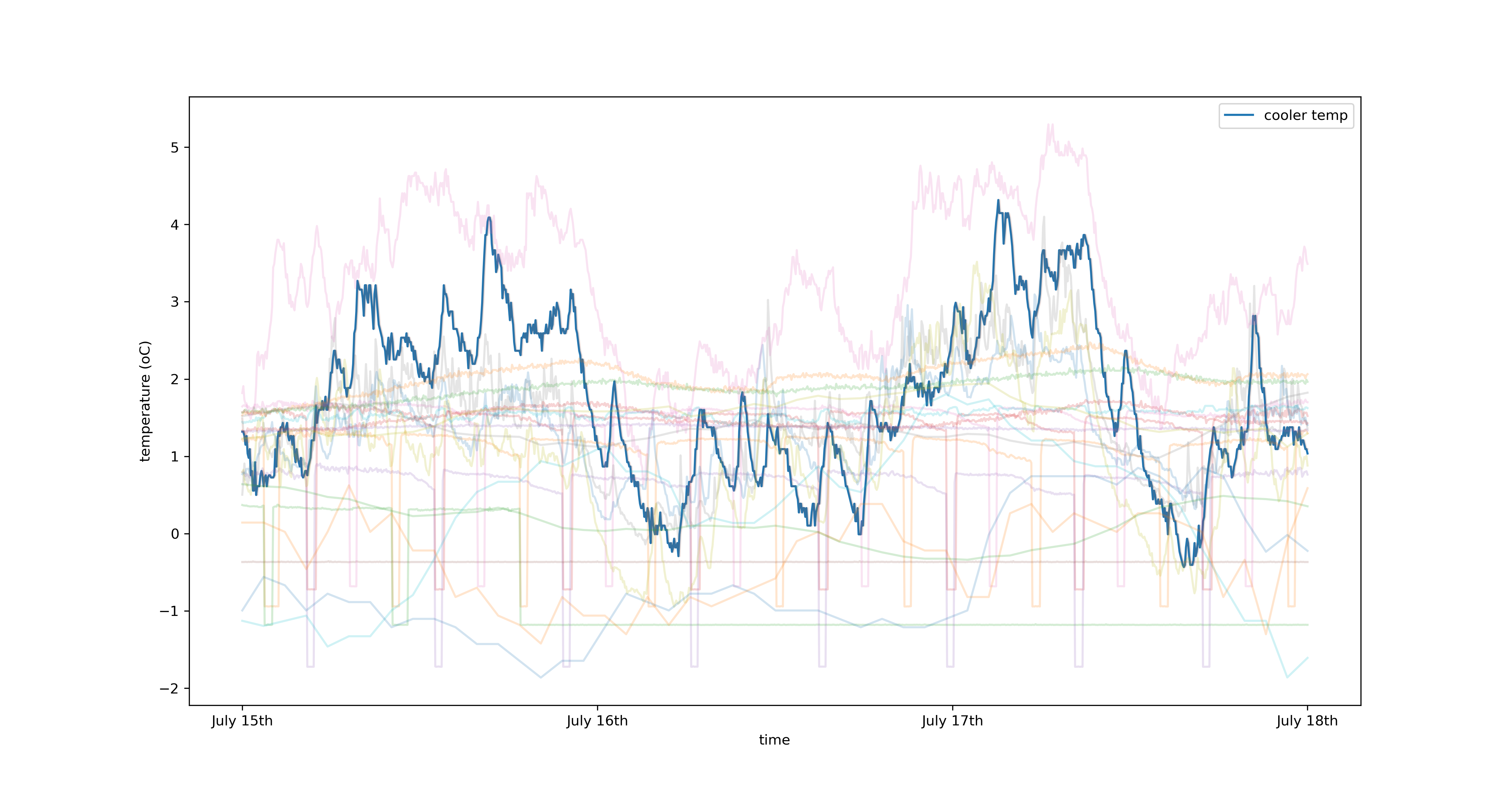
Plotted in blue is the temperature of the coldstore in degrees centigrade sampled at 3 minute intervals. The washed out lines represent features of the system I believe affect the temperature of the coldstore, there are 40 in total. These include but are not limited to:
- Outside weather
- Power usage in the chillers
- Wall/floor temperature
- etc.
I model the temperature as a function of these inputs at some number of timesteps prior to the timestep of interest for both a neural network (specifically an LSTM, see this excellent blog post for more info) and a GP. The output of the LSTM is a function of the 10 previous timesteps and the GP is a function of only the previous timestep. Here are the results, firstly the LSTM:
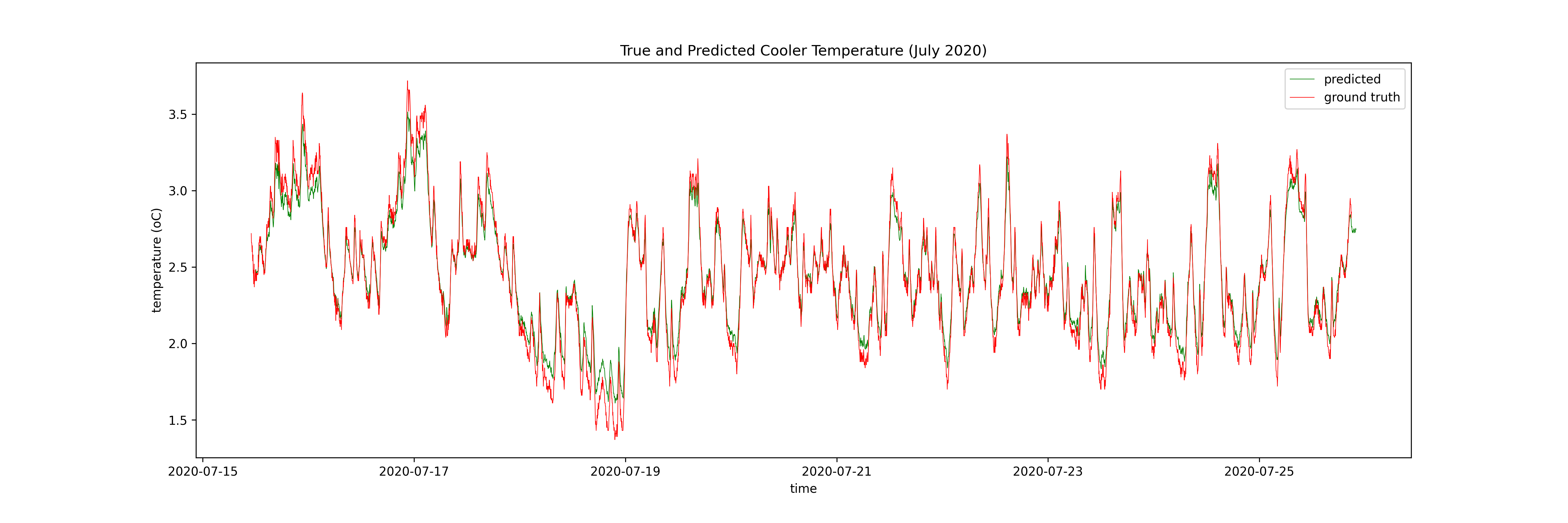
Then the GP:
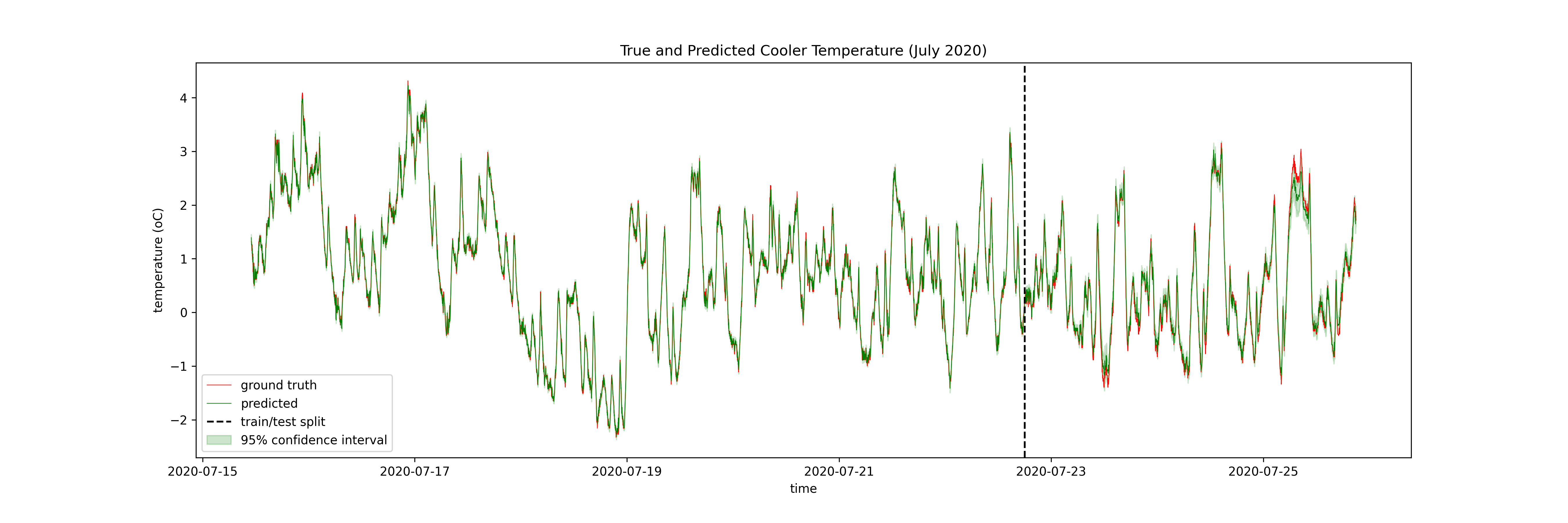
Then only the test set of the GP:

I have 9 months of data at the coldstorage facility (N ~ 400,000). The advantage of the LSTM is that it can use all of this data, meaning it can explore more of the state space, and make better predictions in those out-of-distribution times. The GP can only use ~10% of the dataset for training, meaning it cannot explore the state space in the same way the neural network can, but it can limit the damage by quantifying its uncertainty.
5. Key Takeaways
- Black box function approximators can model any continuous function in theory
- Deterministic techniques effective with large (N > $10^5$) datasets
- Probabilistic techniques more robust in low data regimes thanks to uncertainty quantification
- GPs are limited by their expensive computations (N must be < $10^5$)
- Both approaches can be used to model complex timeseries datasets
Further Reading
Further explanations on why these techniques work
How can you build these in practice?
- Neural nets: Introduction to deep learning with tensorflow
- GPs: GP regression on molecules
- LSTMs: LSTMs for timeseries prediction
Introductory Books
- The art of statistics: how to learn from data - David Spiegelhalter (2018)
- Life 3.0: Being Human in the Age of Artificial Intelligence - Max Tegmark (2017)
Thanks!
- Notes: https://enjeeneer.io/talks/2021-03-15-xchangeseminar/
- Thanks to Carl Henrik Ek, Dept. of Computer Science for inspiring these slides
- Questions?
References
[1] Mnih, Volodymyr, et al. “Playing Atari with deep reinforcement learning.” arXiv preprint arXiv:1312.5602 (2013).
[2] Silver, David, et al. “Mastering the game of Go with deep neural networks and tree search.” nature 529.7587 (2016): 484-489.
[3] Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. MIT press, 2018.
[4] Rasmussen, Carl Edward. “Gaussian processes in machine learning.” Summer school on machine learning. Springer, Berlin, Heidelberg, 2003.
machine learning rl black-box functions
f4b2b0c @ 2022-02-25